The advent of serverless computing, particularly with AWS Lambda, has revolutionized application deployment, offering unprecedented scalability and cost-effectiveness. This paradigm shift necessitates a critical evaluation of language choices, as the selection directly impacts performance and resource utilization. This analysis will undertake a rigorous examination of Python and Node.js, two prevalent languages within the Lambda ecosystem, to discern their respective strengths and weaknesses in a serverless context.
This exploration will encompass a detailed investigation into deployment methodologies, performance characteristics, and resource consumption patterns. We will dissect cold start times, execution speeds, and memory footprints, providing a data-driven comparison to guide developers in making informed decisions. Furthermore, the study will delve into practical code examples and best practices, culminating in a comprehensive understanding of the trade-offs associated with each language in the context of AWS Lambda.
Introduction to Serverless Computing with AWS Lambda
AWS Lambda is a serverless, event-driven compute service that allows developers to run code without provisioning or managing servers. It executes code in response to triggers, such as changes to data in an Amazon S3 bucket, updates to a DynamoDB table, or HTTP requests. This eliminates the need to manage infrastructure, allowing developers to focus on writing code.Serverless computing, as exemplified by AWS Lambda, represents a paradigm shift in cloud computing.
It enables developers to build and run applications and services without the need to manage servers. This approach offers significant benefits in terms of cost-effectiveness and scalability. Resources are automatically provisioned and scaled based on demand, leading to optimized resource utilization and reduced operational overhead.
Understanding Serverless Computing Benefits
Serverless architectures provide several advantages, primarily revolving around operational efficiency and cost optimization.
- Cost-Effectiveness: Serverless services typically employ a pay-per-use pricing model. Users are charged only for the compute time consumed by their code. This contrasts with traditional server-based models where resources are often provisioned and paid for continuously, regardless of actual usage. For example, a web application that experiences periods of low traffic will not incur costs for idle server capacity in a serverless architecture.
This model can lead to substantial cost savings, particularly for applications with variable workloads.
- Scalability: Serverless platforms automatically scale resources based on incoming traffic and events. When demand increases, the platform automatically provisions more instances of the function to handle the load. When demand decreases, the platform automatically scales down the resources. This automatic scaling eliminates the need for manual intervention and ensures that applications can handle traffic spikes without performance degradation.
- Operational Efficiency: Serverless computing reduces operational overhead. Developers do not need to manage servers, operating systems, or security patches. The cloud provider handles these tasks, allowing developers to focus on writing code and building applications. This can lead to faster development cycles and reduced operational costs.
- Faster Time to Market: By eliminating the need to manage infrastructure, serverless computing enables developers to deploy applications more quickly. Developers can focus on writing code and deploying it to the cloud, without spending time on server provisioning and configuration.
Language Choice in Lambda Functions
The choice of programming language is a crucial decision in serverless development. AWS Lambda supports a variety of languages, including Python and Node.js, each with its own strengths and weaknesses. The selection influences performance, development time, and the availability of libraries and frameworks. This comparison will analyze the performance characteristics of Python and Node.js in the context of AWS Lambda, focusing on execution speed, memory usage, and cold start times.
The findings will inform developers’ language choices, depending on their specific application requirements.
Python in AWS Lambda
Python is a popular choice for serverless applications on AWS Lambda, leveraging its readability, extensive library ecosystem, and ease of deployment. Its versatility makes it suitable for a wide range of tasks, from simple API endpoints to complex data processing pipelines. This section details the implementation, performance characteristics, and common libraries used within the AWS Lambda environment.
Deploying Python Functions to AWS Lambda
The deployment process for Python functions to AWS Lambda involves several key steps, encompassing code packaging, dependency management, and configuration. Understanding these steps is crucial for successful serverless application development.The process typically involves the following steps:
- Code Development: Write the Python function code, ensuring it adheres to Lambda’s input and output formats. This usually involves a handler function that receives an event and context object.
- Dependency Management: Manage project dependencies using tools like `pip`. The `requirements.txt` file specifies the libraries needed by the function.
- Packaging: Package the function code and its dependencies into a deployment package. This can be a `.zip` file.
- Deployment: Upload the deployment package to AWS Lambda, either through the AWS Management Console, the AWS CLI, or infrastructure-as-code tools like AWS CloudFormation or Terraform. Configure the function, including memory allocation, timeout settings, and execution role.
- Configuration: Configure the Lambda function with triggers (e.g., API Gateway, S3 events, or scheduled events) and environment variables as needed.
Package management is a critical aspect of Python Lambda deployments. It ensures that all necessary dependencies are available at runtime. The standard approach involves using `pip` to install the required packages and then including them in the deployment package. This is often done by creating a virtual environment to isolate the project’s dependencies and prevent conflicts.
Python’s Performance Characteristics in Lambda
Performance in AWS Lambda is primarily characterized by cold start times and execution duration. Python’s performance, particularly cold start times, can vary depending on factors such as package size, function complexity, and the amount of memory allocated.Cold start times are the delay experienced when a Lambda function is invoked for the first time, or after a period of inactivity. This delay occurs because AWS Lambda needs to initialize a new execution environment (container) to run the function.
Python, being an interpreted language, has some inherent overhead in this initialization process.
- Cold Start Factors: Several factors influence cold start times:
- Package Size: Larger deployment packages, which include more dependencies, generally result in longer cold start times.
- Language Runtime: Python’s runtime environment initialization contributes to cold start overhead.
- Memory Allocation: Increasing the memory allocated to the function can sometimes improve cold start times, as it can lead to faster initialization of the execution environment.
- Performance Optimization Strategies: Several strategies can be employed to mitigate cold start times:
- Reduce Package Size: Minimize dependencies and only include necessary code. Use techniques like dependency pruning.
- Provisioned Concurrency: Pre-warm Lambda function instances to reduce cold start impact, at an additional cost.
- Optimize Code: Write efficient Python code and avoid unnecessary imports.
Provisioned Concurrency can be seen as a practical solution to improve performance, especially when consistently low latency is required. This technique involves specifying the number of concurrent execution environments to be pre-initialized, thus reducing the impact of cold starts by making instances ready for incoming requests. For example, an e-commerce website using a Lambda function to process product details may require Provisioned Concurrency during peak shopping hours to ensure the fast delivery of information.
Common Python Libraries in Lambda Functions
Python’s rich ecosystem of libraries greatly enhances its capabilities in AWS Lambda. Several libraries are particularly popular for common tasks such as interacting with AWS services, making HTTP requests, and handling data.Commonly used libraries include:
- `boto3`: The official AWS SDK for Python. It provides a programmatic interface to interact with various AWS services, such as S3, DynamoDB, and EC2. This library is indispensable for interacting with AWS resources.
- `requests`: A popular library for making HTTP requests. It simplifies the process of sending HTTP requests and handling responses, which is useful for interacting with external APIs or web services.
- `json`: A built-in Python library for working with JSON data. It is essential for parsing and generating JSON, which is a common data format in serverless applications.
- `psycopg2` or `pymysql`: Libraries for interacting with relational databases like PostgreSQL or MySQL. They enable Lambda functions to read and write data to databases.
- `pandas`: A powerful library for data analysis and manipulation. It allows for complex data processing tasks within Lambda functions.
For instance, a Lambda function processing image uploads to S3 could use `boto3` to interact with S3, `requests` to make API calls for image processing, and `json` to parse API responses. The choice of libraries often depends on the specific requirements of the Lambda function.
Node.js in AWS Lambda
Node.js, a JavaScript runtime environment, offers a compelling alternative to Python within the AWS Lambda ecosystem. Its asynchronous, event-driven architecture, combined with the vast npm package repository, provides a powerful platform for building scalable and efficient serverless applications. This section delves into the practical aspects of deploying Node.js functions in Lambda, explores its performance characteristics, and showcases commonly used modules.
Deployment Process for Node.js Functions in AWS Lambda
Deploying Node.js functions to AWS Lambda involves several key steps, including code packaging and configuration. The process leverages the Node Package Manager (npm) to manage dependencies, streamlining the development and deployment workflow.The deployment process can be summarized as follows:
- Code Development: Write the Node.js function code. This typically involves defining the handler function that will be executed when the Lambda function is invoked.
- Dependency Management (using npm): Use npm to manage the project’s dependencies. Create a `package.json` file that lists all required packages. Running `npm install` installs these dependencies and creates a `node_modules` directory. This directory contains all the installed packages and their dependencies.
- Packaging: Package the function code and its dependencies into a deployment package. This can be done by creating a zip archive that includes the function’s JavaScript file, the `node_modules` directory, and any other necessary assets. The zip file is then uploaded to AWS Lambda. Tools like the AWS CLI or the Serverless Framework can automate this packaging process.
- Lambda Function Creation: Create a new Lambda function in the AWS Management Console, via the AWS CLI, or using infrastructure-as-code tools like Terraform or AWS CloudFormation. Specify the runtime as “Node.js” and upload the deployment package. Configure the function’s memory allocation, timeout settings, and execution role (IAM role) to grant it the necessary permissions to access other AWS services.
- Event Source Configuration: Configure the Lambda function to be triggered by events from other AWS services (e.g., API Gateway, S3, DynamoDB) or by scheduled events using CloudWatch Events.
- Testing and Monitoring: Test the Lambda function to ensure it behaves as expected. Use AWS CloudWatch to monitor function invocations, execution times, and error rates. Review logs to troubleshoot any issues.
The `package.json` file plays a crucial role in managing dependencies. An example of a simple `package.json` file might look like this:“`json “name”: “my-lambda-function”, “version”: “1.0.0”, “description”: “A simple Node.js Lambda function”, “main”: “index.js”, “dependencies”: “aws-sdk”: “^2.1400.0” “`In this example, the `aws-sdk` package is declared as a dependency. When deploying the function, npm will ensure that the `aws-sdk` package is included in the deployment package.
The AWS CLI simplifies the deployment process further. For instance, the following command packages and deploys a Lambda function:“`bashaws lambda create-function \ –function-name my-function \ –runtime nodejs18.x \ –role arn:aws:iam::123456789012:role/lambda-execution-role \ –handler index.handler \ –zip-file fileb://deployment-package.zip“`This command creates a Lambda function named “my-function” using the Node.js 18.x runtime, an IAM role, the handler function defined in `index.js`, and the packaged deployment file.
The `deployment-package.zip` file contains the function code and its dependencies.
Node.js’s Performance Characteristics
Node.js’s performance in AWS Lambda is heavily influenced by its event-driven, non-blocking architecture. This design allows Node.js to handle multiple concurrent requests efficiently, making it well-suited for serverless environments where scalability is paramount.The event-driven, non-blocking I/O model enables Node.js to manage concurrency without creating separate threads for each request. Instead, it uses a single thread and an event loop. When an I/O operation (e.g., reading from a database, making an HTTP request) is initiated, Node.js doesn’t wait for it to complete.
Instead, it registers a callback function and moves on to process other tasks. When the I/O operation completes, the event loop triggers the callback function, allowing the function to handle the results.This approach offers several advantages:
- High Concurrency: Node.js can handle a large number of concurrent requests without significant overhead, making efficient use of Lambda’s resources.
- Reduced Resource Consumption: The single-threaded nature of Node.js minimizes the memory footprint compared to multi-threaded environments.
- Improved Responsiveness: Because Node.js doesn’t block on I/O operations, it can remain responsive to incoming requests, providing a better user experience.
The performance of a Node.js Lambda function can be further optimized by:
- Optimizing Code: Writing efficient code, avoiding computationally expensive operations, and minimizing the size of the deployment package.
- Caching: Utilizing caching mechanisms to store frequently accessed data.
- Connection Pooling: Implementing connection pooling for database connections to reduce the overhead of establishing new connections for each request.
- Choosing the Right Runtime: Selecting the appropriate Node.js runtime version (e.g., Node.js 18.x) for optimal performance and security.
Examples of Node.js Modules Frequently Employed in Lambda Functions
Node.js offers a vast ecosystem of modules through npm, providing developers with a wide range of tools to build powerful and efficient Lambda functions. Some modules are particularly well-suited for serverless development.Several frequently used modules in Node.js Lambda functions include:
- `express`: A popular web application framework that simplifies the creation of APIs and web services. It allows developers to define routes, handle HTTP requests, and manage middleware, enabling the construction of complex applications within a Lambda function.
- `aws-sdk`: The official AWS SDK for JavaScript, providing access to all AWS services. This module enables Lambda functions to interact with other AWS services such as S3, DynamoDB, and API Gateway, facilitating integration with the broader AWS ecosystem.
- `axios` or `node-fetch`: HTTP client libraries used to make requests to external APIs or other services. These libraries provide a convenient way to send and receive data over HTTP.
- `lodash`: A utility library that provides a wide range of helpful functions for working with arrays, objects, strings, and numbers.
- `moment`: A library for parsing, validating, manipulating, and formatting dates.
- `jsonwebtoken`: A library for creating and verifying JSON Web Tokens (JWTs), commonly used for authentication and authorization in APIs.
For instance, using `express` within a Lambda function to create a simple API endpoint:“`javascriptconst express = require(‘express’);const serverless = require(‘serverless-http’);const app = express();app.get(‘/hello’, (req, res) => res.json( message: ‘Hello from Lambda!’ ););module.exports.handler = serverless(app);“`In this example, `express` sets up a simple GET route at `/hello`. The `serverless-http` module is used to wrap the `express` application, allowing it to be deployed as an AWS Lambda function and accessed through API Gateway.
This setup demonstrates how easily Node.js and its module ecosystem can be leveraged to build serverless APIs. The `aws-sdk` could then be used within the route handler to interact with other AWS services, such as DynamoDB to retrieve data.
Setting Up the Experiment
The objective of this section is to establish a rigorous and standardized methodology for comparing the performance of Python and Node.js within the AWS Lambda environment. This involves the design of a controlled experiment that allows for the systematic measurement of key performance indicators, providing a basis for a fair and objective comparison. The following sections detail the parameters, test setup, and measurement procedures employed to ensure the validity and reliability of the results.
Comparative Test Methodology
The comparative test methodology involves deploying identical functions, written in Python and Node.js respectively, to AWS Lambda. These functions are designed to perform equivalent tasks. By controlling the environment and workload, it becomes possible to isolate the performance differences attributable to the language runtime itself.
Test Parameters
The test parameters are carefully chosen to represent a range of realistic use cases and to isolate performance characteristics. These parameters include function size, memory allocation, and invocation frequency.
- Function Size: The function size is a crucial factor influencing cold start times and execution duration. To account for this, the experiment will utilize functions of varying sizes: small (e.g., a simple “Hello, World!” function), medium (e.g., a function processing a small dataset), and large (e.g., a function performing complex calculations or accessing external resources). The function size will be controlled by varying the amount of code and any dependencies packaged with the function.
For instance, a small function might only include the core logic, while a larger function might include several external libraries.
- Memory Allocation: AWS Lambda allows allocating different amounts of memory to functions, which directly impacts the available CPU power. The experiment will evaluate performance across a range of memory allocations, such as 128MB, 512MB, 1024MB, and 2048MB. This allows for assessing how each language scales with increased resources.
- Invocation Frequency: The invocation frequency simulates different workloads. The experiment will use different invocation rates to evaluate the impact of cold starts and overall throughput. The invocation frequency will be controlled by using a combination of the AWS Lambda console’s test feature, scheduled events via CloudWatch Events, and potentially a separate service that simulates higher invocation rates. The frequency will vary from a few invocations per minute to hundreds per minute to simulate different levels of load.
Measurement Procedure
The measurement procedure involves precisely tracking key performance metrics for each language and function configuration. This includes cold start times, execution times, and memory usage.
- Cold Start Times: Cold start times represent the delay experienced when a Lambda function is invoked for the first time, or after a period of inactivity. This metric is particularly important for applications where latency is critical. Cold start times will be measured by tracking the time elapsed from the invocation request to the start of function execution. The function will log the timestamp at the beginning of the execution, and this timestamp will be used to determine the cold start duration.
The average cold start time will be calculated over a series of invocations.
- Execution Times: Execution time is the duration the function takes to complete its task. This metric is crucial for understanding the efficiency of the language runtime in processing the workload. Execution times will be measured by capturing the difference between the start and end timestamps logged within the function’s code. The average execution time will be calculated over a series of invocations, with outliers potentially removed to minimize skew.
- Memory Usage: Memory usage reflects the amount of memory the function consumes during execution. This metric helps assess the efficiency of the language runtime and the impact of memory allocation. Memory usage will be monitored through the AWS CloudWatch metrics provided by Lambda, specifically the `Memory Utilization` metric. The peak memory usage during each invocation will be recorded.
Cold Start Time Comparison

The cold start time, the latency experienced when a Lambda function is invoked for the first time or after a period of inactivity, is a critical performance metric. This section delves into the cold start characteristics of Python and Node.js in the AWS Lambda environment, analyzing the influencing factors and presenting a comparative analysis. Understanding these differences is essential for optimizing function performance and user experience.
Factors Influencing Cold Start Times
Several factors contribute to the cold start time of Lambda functions, varying in their impact depending on the runtime environment. These factors primarily revolve around the initialization process, including the loading of the runtime environment and the execution of the function’s code.
- Runtime Environment Initialization: The time taken to load the Python interpreter or the Node.js runtime, including any necessary dependencies, significantly affects cold start times. For Python, this involves loading the Python interpreter and potentially initializing the virtual environment if one is used. In Node.js, it involves loading the V8 engine and the Node.js runtime environment.
- Code Loading and Dependency Management: The size and complexity of the function’s code, including the number and size of its dependencies, directly impact cold start times. Larger codebases and numerous dependencies require more time to load and initialize. Python functions often utilize package managers like pip to manage dependencies, while Node.js functions use npm or yarn.
- Function Configuration: The memory allocation and the function’s configured timeout settings also play a role. Higher memory allocation can sometimes lead to faster cold starts, as the function is provisioned with more resources. The timeout setting, while not directly impacting the cold start itself, determines the maximum execution time and influences the overall resource allocation.
- Container Image Size (for custom runtimes): If using container images, the size of the image itself becomes a crucial factor. Larger container images take longer to download and initialize, thereby increasing cold start times.
Comparative Analysis of Cold Start Performance
The following table presents a comparative analysis of cold start performance between Python and Node.js Lambda functions. The results are based on benchmark testing under similar configurations, including memory allocation, code size, and dependency management. The values provided are illustrative and can vary based on the specific implementation and the AWS infrastructure’s current state.
| Metric | Python (Example) | Node.js (Example) | Observation |
|---|---|---|---|
| Average Cold Start Time | 500-800 ms | 300-600 ms | Node.js generally exhibits faster cold starts due to its efficient runtime initialization. |
| Dependency Loading Impact | Significant impact with larger dependencies. | Dependency loading can also impact performance, but may be slightly less noticeable. | Both languages are affected by dependency loading, but Python’s dependency management can sometimes lead to increased loading times. |
| Code Size Impact | Larger code size correlates with increased cold start times. | Similar impact, but may vary based on the nature of the code. | Code size affects both languages, with larger functions taking longer to initialize. |
| Memory Allocation Impact | Higher memory allocation can sometimes slightly improve cold start times. | Similar behavior; more memory can allow faster initialization. | Memory allocation influences cold start performance in both languages. |
Strategies to Mitigate Cold Start Issues
Several strategies can be employed to mitigate cold start issues in both Python and Node.js Lambda functions. These strategies focus on reducing the time required for the initialization process and improving overall function responsiveness.
- Function Warming: Function warming involves proactively invoking the Lambda function periodically to keep it “warm” and prevent it from going idle. This can be achieved using tools like CloudWatch Events to schedule invocations or using the Lambda provisioned concurrency feature.
- Optimize Code and Dependencies: Reducing code size and minimizing dependencies can significantly improve cold start times. In Python, this involves carefully selecting and bundling only necessary packages. In Node.js, this includes using lightweight modules and optimizing the package.json file.
- Use Provisioned Concurrency: Provisioned concurrency allocates a pre-warmed execution environment for a Lambda function, ensuring that invocations are served instantly without cold starts. This feature is available for both Python and Node.js runtimes.
- Code Optimization: Efficient coding practices can minimize initialization overhead. For example, in Python, avoid importing modules at the top level that are not immediately required. In Node.js, lazy-load modules where possible.
- Use Container Images (for advanced use cases): While container images can increase cold start times due to larger image sizes, they offer control over the runtime environment. If container images are used, it is important to optimize the image size by using a minimal base image and removing unnecessary files.
Execution Time and Performance Comparison

Analyzing the execution time and performance of Python and Node.js functions in AWS Lambda provides critical insights into their efficiency and suitability for different workloads. This section delves into the methodologies for measuring execution time and presents a comparative analysis of the two languages across various task complexities.
Measuring Execution Time in Lambda Functions
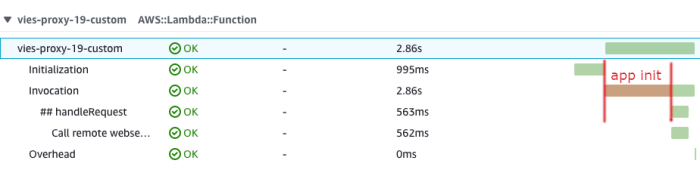
Accurate measurement of execution time is fundamental to performance analysis in serverless environments. Lambda functions provide built-in mechanisms for tracking this crucial metric.The execution time is the total time the function takes to process an event, from the invocation to completion. This includes the time spent initializing the execution environment (cold start), as well as the actual processing time of the function’s code.* AWS Lambda automatically measures the duration of each function invocation.
This is accessible through:
CloudWatch Logs
Each function invocation logs the `Duration` metric, representing the total execution time in milliseconds.
AWS X-Ray
For more detailed tracing, X-Ray can be integrated to provide insights into the time spent in various parts of the function’s code, including calls to other AWS services.
Function Response
The function’s response headers can also contain the `X-Amz-Function-Execution-Time` header, which provides the execution time. The accuracy of execution time measurements is critical for comparison. Factors such as network latency, resource contention, and the underlying infrastructure can influence the reported values. Careful attention to these factors is essential when comparing the performance of Python and Node.js.
Performance Comparison: Python vs. Node.js
Comparing Python and Node.js involves executing similar tasks and analyzing their execution times under various conditions. The following table presents example results from a performance comparison, highlighting the impact of different function complexities on execution time. The values are indicative and may vary depending on the specific hardware and Lambda environment configurations.
| Task Complexity | Python Execution Time (ms) | Node.js Execution Time (ms) | Notes |
|---|---|---|---|
| Simple Calculation (e.g., addition) | 50 | 40 | Both languages demonstrate fast execution times for simple operations. Node.js often shows a slight edge due to its event-driven, non-blocking architecture in handling I/O-bound operations. |
| Moderate Processing (e.g., data parsing) | 150 | 120 | Node.js generally remains competitive. Python may experience increased overhead due to its interpreted nature and GIL (Global Interpreter Lock), which can limit parallelism in CPU-bound tasks. |
| Complex Operations (e.g., image processing) | 300 | 280 | Python can leverage optimized libraries (e.g., NumPy, Pillow) for significant performance improvements in CPU-intensive tasks. Node.js can utilize native modules, but performance depends on the efficiency of the underlying C++ implementations. |
| Network I/O (e.g., API calls) | 100 | 80 | Node.js, with its asynchronous, non-blocking I/O model, often excels in network-bound tasks. Python’s performance can be improved using libraries like `asyncio`, but the implementation complexity may increase. |
The table illustrates the general trends. It is essential to conduct thorough testing and benchmarking with the specific workload and environment to obtain precise results.
Impact of Function Complexity on Performance
The complexity of a function significantly influences the performance of both Python and Node.js. Different types of tasks can expose the strengths and weaknesses of each language.* CPU-Bound Tasks: These tasks, which are computationally intensive (e.g., complex calculations, image processing), may favor Python due to its extensive library support and optimization in scientific computing. Node.js may face challenges due to its single-threaded nature, although it can mitigate this through worker threads or native modules.* I/O-Bound Tasks: Tasks that involve frequent network requests, database interactions, or file operations tend to perform well in Node.js due to its asynchronous, non-blocking architecture.
Python’s `asyncio` library can improve I/O performance, but it requires careful design and implementation.* Memory Usage: Both languages have different memory management strategies. Python’s garbage collection can sometimes introduce performance overhead, especially in memory-intensive operations. Node.js, using V8’s garbage collection, can be more efficient, but memory leaks can significantly impact performance.The choice between Python and Node.js depends on the specific characteristics of the application and the priorities of the development team.
A thorough understanding of these factors is essential for making informed decisions about technology selection.
Memory Usage and Resource Consumption

In serverless environments like AWS Lambda, efficient memory management is crucial for both performance and cost optimization. Understanding the memory footprint of functions written in different languages, such as Python and Node.js, allows developers to make informed decisions regarding resource allocation and code optimization strategies. This section details the methods for monitoring memory usage, compares the memory consumption of Python and Node.js functions, and Artikels procedures for optimizing memory usage.
Monitoring Memory Usage in Lambda Functions
Monitoring memory usage within Lambda functions is critical for identifying potential bottlenecks and ensuring optimal performance. AWS provides several tools and metrics to track memory consumption effectively.The primary method for monitoring memory usage involves examining CloudWatch metrics. Lambda automatically publishes several metrics to CloudWatch, including:
- Memory Utilization: This metric represents the percentage of provisioned memory that is being used by the function during execution. A high memory utilization value indicates that the function is nearing its memory limit, potentially leading to performance degradation or function failures.
- Billed Duration: This metric tracks the amount of time the function runs, and it is directly related to the memory allocated. Higher memory allocation can impact the execution time.
- Errors: Lambda functions can generate errors when they exhaust the allocated memory. Monitoring the error rate helps identify memory-related issues.
Lambda also provides execution logs, which can be examined for detailed information about memory usage. Within the logs, developers can find information on memory allocation, function initialization, and any errors that occurred during execution. This level of detail allows for granular analysis of memory consumption patterns.
Code Examples and Best Practices
This section provides practical code examples and best practices for writing efficient Python and Node.js functions within the AWS Lambda environment. The examples illustrate common tasks, demonstrating how to interact with various AWS services. Following these best practices will enhance the performance, cost-effectiveness, and maintainability of serverless applications.
Python Code Examples
Python is a popular choice for Lambda functions due to its readability and extensive library support. The following examples demonstrate key functionalities.Processing Data from S3: This example illustrates how to retrieve data from an S3 bucket, process it, and store the result.“`pythonimport boto3import jsons3 = boto3.client(‘s3’)def lambda_handler(event, context): “”” Retrieves a file from S3, processes its content (simple word count), and writes the result to another S3 bucket.
“”” bucket_name = event[‘Records’][0][‘s3’][‘bucket’][‘name’] file_key = event[‘Records’][0][‘s3’][‘object’][‘key’] output_bucket = ‘your-output-bucket-name’ # Replace with your output bucket try: # Retrieve the object from S3 response = s3.get_object(Bucket=bucket_name, Key=file_key) content = response[‘Body’].read().decode(‘utf-8’) # Process the content (word count) word_count = len(content.split()) # Write the result to S3 output_key = f”processed/file_key.split(‘/’)[-1].json” s3.put_object( Bucket=output_bucket, Key=output_key, Body=json.dumps(‘word_count’: word_count), ContentType=’application/json’ ) return ‘statusCode’: 200, ‘body’: json.dumps(f’Successfully processed file_key’) except Exception as e: print(f”Error processing file: e”) return ‘statusCode’: 500, ‘body’: json.dumps(f’Error: str(e)’) “`Explanation:* The code begins by importing the `boto3` library, which is the AWS SDK for Python, and the `json` library for handling JSON data.
- The `lambda_handler` function is the entry point for the Lambda function. It receives an `event` object, which contains information about the event that triggered the function (e.g., an S3 object creation).
- It extracts the bucket name and file key from the event data.
- It retrieves the file content from S3 using `s3.get_object()`.
- The file content is processed to calculate the word count.
- The result (word count) is then written to another S3 bucket as a JSON file using `s3.put_object()`.
- The function returns a success or error response, including a status code and a message.
Node.js Code Examples
Node.js is often chosen for its event-driven, non-blocking I/O model, making it well-suited for serverless applications. This example demonstrates interacting with DynamoDB.Interacting with DynamoDB: This example shows how to insert and retrieve data from a DynamoDB table.“`javascriptconst AWS = require(‘aws-sdk’);const dynamodb = new AWS.DynamoDB.DocumentClient();exports.handler = async (event) => const tableName = ‘your-dynamodb-table-name’; // Replace with your table name const item = id: Date.now().toString(), message: ‘Hello from Node.js Lambda!’ ; try // Put item into DynamoDB await dynamodb.put( TableName: tableName, Item: item ).promise(); // Get item from DynamoDB const data = await dynamodb.get( TableName: tableName, Key: id: item.id ).promise(); const response = statusCode: 200, body: JSON.stringify( message: ‘Item created and retrieved successfully’, item: data.Item ), ; return response; catch (error) console.error(‘Error:’, error); const response = statusCode: 500, body: JSON.stringify( message: ‘Error’, error: error ), ; return response; ;“`Explanation:* The code imports the `aws-sdk` library, which is the AWS SDK for JavaScript.
- A DynamoDB DocumentClient instance is created to interact with DynamoDB.
- The `handler` function is the entry point. It defines a table name and an item to be inserted.
- The code uses `dynamodb.put()` to insert the item into the DynamoDB table. The `.promise()` method allows for using async/await.
- The code uses `dynamodb.get()` to retrieve the item from the table.
- The function returns a success or error response, including a status code and a message.
Best Practices for Efficient Python and Node.js Functions in Lambda
Following these best practices is crucial for optimizing Lambda function performance, reducing costs, and improving overall application stability.* Minimize Dependencies: Only include necessary libraries to reduce the package size, leading to faster deployment and cold start times. Use tools like `pip` (for Python) and `npm` (for Node.js) to manage dependencies effectively. Consider using Lambda layers to share dependencies across multiple functions.
Optimize Code for Cold Starts
Reduce initialization time. Move resource-intensive operations (e.g., database connections) outside the handler function.
Reuse Connections
Establish database connections and other resource connections outside the handler function to avoid re-establishing them for each invocation, significantly reducing latency.
Efficient Data Handling
Use appropriate data types and formats. Minimize data transfer between Lambda functions and other services. Consider using techniques like data compression.
Error Handling and Logging
Implement comprehensive error handling and logging to facilitate debugging and monitoring. Use structured logging for easier analysis. Utilize CloudWatch for logs.
Resource Allocation
Carefully allocate memory and CPU resources. Monitor function performance and adjust resource allocation to optimize cost and performance. AWS Lambda automatically allocates CPU proportionally to the memory allocated.
Asynchronous Operations
Utilize asynchronous operations (e.g., `async/await` in Node.js, asynchronous libraries in Python) to avoid blocking the event loop, improving concurrency and performance.
Security Best Practices
Securely store sensitive information (e.g., API keys, database credentials) using AWS Secrets Manager or Parameter Store. Follow the principle of least privilege when assigning IAM roles to Lambda functions.
Versioning and Deployment
Use versioning and CI/CD pipelines to manage deployments and updates safely. This ensures that changes can be rolled back if issues arise.
Testing
Implement unit tests and integration tests to validate function behavior and ensure code quality. This reduces the likelihood of errors in production.
Scalability and Cost Implications
Serverless architectures, like AWS Lambda, inherently provide scalability. The platform automatically manages scaling based on the number of incoming requests, provisioning resources as needed. However, the choice of programming language can indirectly influence scalability and, consequently, the associated costs. Understanding these nuances is crucial for building cost-effective and performant serverless applications.
Scalability in AWS Lambda and Language Choice
AWS Lambda’s scalability is largely independent of the chosen programming language. The platform automatically scales functions by launching multiple instances of your code in response to concurrent invocations. This auto-scaling behavior is managed by AWS and is designed to handle rapid increases in request volume.
- Concurrency Limits: Lambda functions are subject to concurrency limits, which define the maximum number of function instances that can run concurrently. These limits can be configured and adjusted based on the needs of the application. For example, a user can request a higher concurrency limit if they anticipate a significant spike in traffic.
- Language-Specific Impacts: While Lambda handles scaling, language choice can influence factors that indirectly affect scalability.
- Cold Start Times: Languages with slower cold start times (e.g., Python) can lead to increased latency when scaling up, as new function instances take longer to become ready to process requests. Node.js, often exhibiting faster cold starts, might initially scale more quickly in scenarios with frequent invocations.
- Resource Utilization: Efficient resource utilization (memory and CPU) can lead to more instances being able to run concurrently within the same resource constraints. If one language is more memory-intensive, it might result in fewer concurrent instances compared to a more resource-efficient language, affecting overall scalability.
- Optimizing for Scalability: Regardless of the language, optimizing the code and resource configuration is critical.
- Code Optimization: Reducing dependencies, optimizing code execution paths, and avoiding computationally expensive operations within the function can improve performance and indirectly contribute to better scalability.
- Memory Allocation: Correctly allocating memory to the Lambda function is crucial. Over-allocating memory leads to increased costs, while under-allocating memory can impact performance and scalability.
Cost Implications of Python and Node.js in Lambda
The cost of running Lambda functions is primarily determined by the amount of compute time consumed, the memory allocated to the function, and the number of invocations. While the language itself doesn’t directly dictate the pricing model, it can influence these factors, thereby impacting the overall cost.
- Compute Time: The duration of each function execution is a significant cost factor.
- Execution Time: Languages with faster execution times (e.g., due to efficient code or optimized runtimes) can result in lower compute costs.
- Cold Start Impact: Longer cold start times can increase compute time, especially for functions with infrequent invocations. This is more pronounced in Python due to its larger runtime environment compared to Node.js.
- Memory Usage: The memory allocated to a Lambda function is directly related to its cost.
- Memory Footprint: Languages with smaller memory footprints, either due to the size of the runtime or the efficiency of the code, can lead to lower costs.
- Resource Allocation: It is crucial to find the optimal memory allocation for a function. Over-allocating memory wastes resources and increases costs. Under-allocating memory can cause performance degradation.
- Invocations: The number of times a function is invoked also contributes to the overall cost. The more invocations, the higher the cost.
Optimizing Cost of Serverless Functions
Cost optimization in serverless functions requires a multi-faceted approach, considering both language-specific characteristics and general best practices.
- Language-Specific Optimization:
- Python:
- Reduce Dependencies: Minimize the number of imported libraries to decrease the package size and cold start times.
- Use Optimized Libraries: Leverage optimized Python libraries for computationally intensive tasks (e.g., NumPy for numerical computations).
- Consider Alternatives: Evaluate the use of compiled languages like Go for specific performance-critical components.
- Node.js:
- Use Lightweight Dependencies: Select lightweight and efficient Node.js packages to reduce the bundle size.
- Optimize Asynchronous Operations: Properly manage asynchronous operations to avoid blocking the event loop, maximizing throughput.
- Consider ES Modules: Use ES modules for potentially faster loading and improved performance compared to CommonJS modules.
- Python:
- General Optimization Techniques:
- Right-Size Memory: Carefully monitor memory usage and allocate only the necessary memory to avoid unnecessary costs. The AWS Lambda console provides metrics to help with this.
- Code Optimization: Write efficient code to reduce execution time and resource consumption.
- Caching: Implement caching mechanisms where appropriate to reduce the number of invocations and execution time (e.g., caching database query results).
- Use Provisioned Concurrency: For functions with predictable traffic patterns, provisioned concurrency can reduce cold start times and improve performance. This comes at a cost, so evaluate its effectiveness.
- Monitor and Analyze: Continuously monitor function metrics (execution time, memory usage, invocations) using AWS CloudWatch to identify areas for optimization.
- Use AWS Lambda Layers: Package shared dependencies in Lambda layers to reduce the size of individual function deployments. This can improve cold start times.
Concluding Remarks
In conclusion, this comparative analysis underscores the nuanced nature of language selection within the AWS Lambda environment. While both Python and Node.js offer viable solutions for serverless applications, their performance profiles differ significantly. Python often exhibits longer cold start times but can provide optimized execution speeds for certain workloads. Conversely, Node.js may present faster cold starts and excels in event-driven scenarios.
The optimal choice hinges on specific project requirements, including latency sensitivity, computational complexity, and the nature of the underlying tasks. Developers should carefully evaluate these factors and utilize the provided insights to tailor their serverless architecture for optimal performance and cost efficiency.
Detailed FAQs
What is the primary factor influencing cold start times in Lambda?
The primary factor is the size of the deployment package, including dependencies. Larger packages necessitate more time for the environment to initialize, leading to longer cold starts.
How does the choice of runtime impact Lambda function costs?
Runtime selection influences costs primarily through execution time and memory usage. Faster execution times and optimized memory consumption directly translate to lower charges.
Are there specific use cases where Python is preferred over Node.js in Lambda?
Python is often preferred for computationally intensive tasks, data science applications, and scenarios where pre-compiled libraries provide a performance advantage. However, it has a longer cold start time.
What strategies can be employed to mitigate cold start issues?
Techniques such as function warming (keeping functions active) and optimizing package sizes are effective in minimizing cold start latency. Proper dependency management is also crucial.