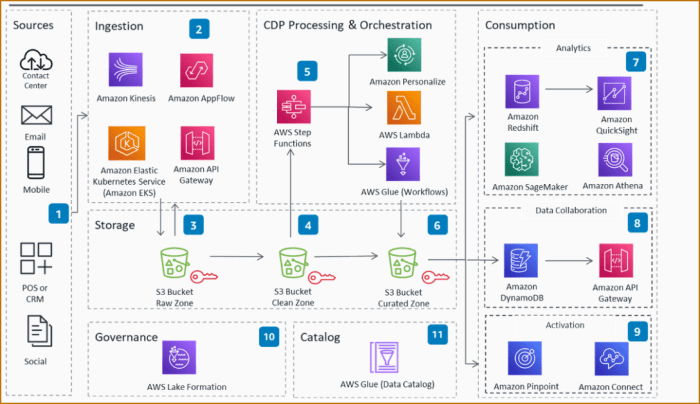
The transition to serverless architectures represents a paradigm shift in software development, promising enhanced scalability, reduced operational costs, and increased developer agility. This comprehensive guide dissects the critical steps involved in refactoring existing applications to embrace the serverless model. We’ll navigate the complexities of migrating from traditional infrastructure to a more flexible, event-driven paradigm, examining the strategic considerations, technical challenges, and best practices essential for a successful transformation.
Refactoring for serverless is not a trivial undertaking; it demands a systematic approach, encompassing architectural analysis, strategic planning, and meticulous implementation. This Artikel provides a structured framework, progressing from initial assessment to deployment and ongoing maintenance, equipping you with the knowledge to confidently navigate this transformative journey. The goal is to provide the necessary information for a smooth transition.
Understanding the Need for Serverless Refactoring

Refactoring existing applications to a serverless architecture is a significant undertaking driven by the desire to optimize various aspects of software development and deployment. This transition often stems from the limitations of traditional infrastructure and the need for increased agility, cost efficiency, and scalability. Serverless refactoring allows businesses to leverage the benefits of cloud computing more effectively, leading to improved performance and reduced operational overhead.
Motivations for Serverless Refactoring
The decision to refactor towards a serverless architecture is usually driven by several key motivations, each addressing specific pain points associated with traditional application deployments. These motivations are often intertwined and contribute to a holistic improvement in the software development lifecycle.
- Cost Optimization: Traditional infrastructure often involves paying for resources even when they are not actively in use. Serverless models, with their pay-per-use pricing, can significantly reduce costs, particularly for applications with fluctuating workloads. For example, an e-commerce platform might see a drastic cost reduction during off-peak hours.
- Enhanced Scalability: Serverless platforms automatically scale resources based on demand. This eliminates the need for manual scaling and allows applications to handle sudden spikes in traffic without performance degradation. Consider the example of a social media application experiencing a viral trend; serverless can automatically allocate the necessary resources.
- Improved Developer Productivity: Serverless platforms abstract away the complexities of infrastructure management. Developers can focus on writing code and building features rather than managing servers, leading to faster development cycles and reduced time-to-market. This can translate into a substantial increase in feature velocity.
- Increased Agility and Flexibility: Serverless architectures enable rapid iteration and experimentation. Deployments are faster, and changes can be rolled out with minimal disruption. This agility is crucial in today’s fast-paced market, allowing businesses to adapt quickly to changing customer needs and market demands.
- Reduced Operational Overhead: Serverless providers handle server provisioning, maintenance, and scaling. This frees up IT teams to focus on more strategic initiatives, reducing the operational burden and associated costs. This can result in significant time savings for IT staff.
Potential Benefits of Serverless Refactoring
Serverless refactoring offers a wide range of benefits that extend beyond the initial motivations. These benefits contribute to a more efficient, cost-effective, and scalable application environment.
- Reduced Operational Expenses: The pay-per-use model of serverless computing minimizes wasted resources, leading to lower operational costs. This is particularly advantageous for applications with variable workloads. For instance, a seasonal business can avoid paying for idle server capacity during off-seasons.
- Improved Scalability and Elasticity: Serverless platforms automatically scale based on demand, ensuring applications can handle peak loads without performance degradation. This elasticity ensures that applications remain responsive even during periods of high traffic.
- Faster Time-to-Market: Serverless development reduces the time required to deploy and update applications. This enables businesses to release new features and updates more quickly, giving them a competitive edge.
- Enhanced Developer Productivity: Developers can focus on coding and building features rather than managing infrastructure. This leads to increased productivity and faster development cycles.
- Increased Resilience and Reliability: Serverless platforms often provide built-in redundancy and fault tolerance, improving application reliability. This reduces the risk of downtime and ensures a better user experience.
- Simplified Deployment and Management: Serverless platforms simplify the deployment process and reduce the need for manual server management. This streamlines operations and reduces the risk of human error.
Scenarios Where Serverless Refactoring is Particularly Advantageous
Certain application types and business contexts are particularly well-suited for serverless refactoring. Understanding these scenarios helps in identifying the best candidates for this architectural shift.
- Event-Driven Applications: Applications that react to events, such as user actions, sensor data, or scheduled tasks, are a natural fit for serverless. Serverless functions can be triggered by events, enabling real-time processing and responsiveness. For example, a system that processes IoT sensor data can leverage serverless functions to analyze data streams in real-time.
- Web and Mobile Backends: Serverless architectures provide an excellent foundation for building scalable and cost-effective backends for web and mobile applications. They can handle user authentication, data storage, and API requests efficiently. An example is a mobile application that uses serverless functions to handle user registration and data synchronization.
- API-Driven Services: Serverless can be used to build and deploy APIs quickly and efficiently. This is particularly useful for microservices architectures, where individual services can be scaled independently. An e-commerce platform could use serverless functions to expose APIs for product search, order processing, and payment gateways.
- Batch Processing and Data Transformation: Serverless functions can be used to process large datasets and transform data in the cloud. This can automate data pipelines and reduce the need for dedicated infrastructure. A company that processes financial transactions might use serverless functions to validate and transform transaction data.
- Applications with Variable Workloads: Serverless is ideally suited for applications with fluctuating traffic patterns. The automatic scaling capabilities ensure that resources are allocated only when needed, optimizing costs. A news website, for instance, can automatically scale its resources to handle increased traffic during breaking news events.
Assessing the Current Application Landscape
Evaluating an existing application for serverless suitability is a critical step in the refactoring process. A thorough assessment allows for informed decision-making, minimizing risks and maximizing the benefits of serverless architecture. This involves a deep dive into the application’s current state, analyzing its various components, and understanding its operational characteristics.
Identifying Key Aspects for Serverless Suitability
Several key aspects must be considered when determining an application’s suitability for serverless transformation. These factors provide a framework for evaluating the potential benefits and challenges of moving to a serverless model.
- Application Architecture: The application’s architectural style significantly influences its serverless compatibility. Monolithic applications often require more extensive refactoring compared to microservices-based architectures. Microservices, with their independent deployability and scalability, are inherently well-suited for serverless environments. The degree of coupling between components is a key indicator; loosely coupled systems are easier to adapt.
- Business Logic Complexity: The complexity of the business logic impacts the feasibility of serverless adoption. Simple, stateless operations are ideal for serverless functions. Complex, stateful processes may require more intricate design patterns, such as orchestrating multiple serverless functions or employing external state management services.
- Traffic Patterns: Understanding the application’s traffic patterns is crucial. Serverless architectures excel at handling variable workloads and scaling on demand. Applications with unpredictable traffic spikes or periods of low utilization can significantly benefit from serverless’s auto-scaling capabilities. Conversely, applications with consistently high, predictable loads may require careful cost optimization strategies in a serverless context.
- Dependencies and Integrations: The application’s dependencies on external services and its integration with other systems play a crucial role. Serverless functions can readily integrate with cloud-based services, such as databases, message queues, and object storage. However, complex integrations or dependencies on legacy systems might present challenges and require careful planning.
- State Management: The application’s approach to state management is a key consideration. Serverless functions are inherently stateless. Applications that rely heavily on in-memory state or session management may need to be redesigned to leverage external state stores, such as databases or caches.
- Security Requirements: The application’s security requirements must be carefully evaluated. Serverless environments offer built-in security features, but they also introduce new considerations, such as function-level access control and the secure handling of secrets. Compliance requirements (e.g., GDPR, HIPAA) need to be assessed within the context of the chosen serverless provider’s security offerings.
- Operational Considerations: Evaluating operational aspects, such as monitoring, logging, and debugging, is essential. Serverless platforms provide tools for monitoring and troubleshooting, but the specific implementation and integration with existing operational practices must be considered.
Analyzing Application Architecture, Dependencies, and Resource Utilization
A detailed analysis of the application’s architecture, dependencies, and resource utilization is necessary to understand its behavior and identify areas for serverless refactoring. This analysis involves a combination of code review, performance testing, and profiling.
- Architecture Review: A comprehensive architectural review helps identify the application’s components, their interactions, and the underlying infrastructure. This review should document the system’s overall structure, including diagrams illustrating the relationships between components and external services. Tools like architectural documentation generators, such as those provided by various cloud providers, can automate parts of this process.
- Dependency Analysis: Analyzing the application’s dependencies is critical. This involves identifying all external libraries, frameworks, and services that the application relies on. Dependency analysis tools, integrated into modern IDEs, can automatically generate dependency graphs. Understanding dependencies helps in determining which components are suitable for serverless migration and which might require more extensive refactoring.
- Code Profiling and Performance Testing: Code profiling and performance testing provide insights into the application’s resource utilization, including CPU, memory, and network I/O. Profiling tools, available in most programming languages and IDEs, can identify performance bottlenecks. Performance testing, such as load testing and stress testing, can simulate realistic workloads and reveal how the application behaves under pressure. The results of these tests help identify areas where serverless functions can improve performance and scalability.
- Resource Utilization Monitoring: Monitoring the application’s resource utilization provides data about its current behavior. Cloud provider-specific monitoring tools, such as AWS CloudWatch, Azure Monitor, and Google Cloud Monitoring, provide detailed metrics on CPU usage, memory consumption, and network traffic. This data is essential for understanding how the application behaves under various load conditions and for identifying opportunities to optimize resource allocation in a serverless environment.
Analyzing the historical data can reveal patterns, like peak loads and idle periods, that can inform serverless function sizing and scaling strategies.
- Database Analysis: Examining the database usage patterns, including queries, read/write ratios, and connection pooling, helps in optimizing database interactions in a serverless environment. Serverless functions typically have short execution times and frequent invocations, potentially leading to connection management challenges. Techniques like connection pooling, serverless-friendly database drivers, and database-as-a-service (DBaaS) offerings can mitigate these issues.
Determining the Scope of the Refactoring Effort
Determining the scope of the refactoring effort involves assessing the complexity of the required changes and estimating the time and resources needed for the transition to serverless. This process typically involves creating a refactoring plan and prioritizing tasks.
- Component-Based Evaluation: Evaluating the application component by component allows for a phased approach to serverless adoption. Identify components that are suitable for serverless migration based on their characteristics, such as statelessness, simplicity, and independent deployability. Prioritize components based on their business value and the potential benefits of serverless.
- Risk Assessment: A risk assessment identifies potential challenges and obstacles during the refactoring process. Consider factors like the complexity of the code, the availability of expertise, and the impact on existing operations. Develop mitigation strategies to address these risks.
- Refactoring Plan Creation: Create a detailed refactoring plan outlining the steps involved in migrating each component to serverless. The plan should include timelines, resource allocation, and testing procedures. Use a phased approach, starting with smaller, less critical components, to minimize risk and gain experience.
- Cost-Benefit Analysis: Conduct a cost-benefit analysis to evaluate the potential return on investment (ROI) of serverless refactoring. This analysis should consider factors like development costs, operational costs, and the potential benefits of serverless, such as increased scalability, reduced infrastructure management, and improved agility.
- Proof of Concept (POC): Implement a proof of concept (POC) to validate the serverless architecture and demonstrate its feasibility. The POC should focus on a small, representative portion of the application. The results of the POC provide valuable insights into the challenges and benefits of serverless adoption.
Defining the Refactoring Strategy
Successfully transitioning to a serverless architecture necessitates a well-defined refactoring strategy. This involves a methodical approach to minimize operational risks and ensure a smooth migration process. A phased approach, prioritizing component selection, and leveraging a decision tree for service selection are crucial elements in this strategy.
Designing a Phased Approach to Serverless Refactoring
Implementing a phased approach is critical to mitigate risks associated with serverless refactoring. This strategy allows for iterative improvements, enabling teams to learn from early experiences and refine their approach before committing to a full-scale migration.
A phased approach typically involves these stages:
- Phase 1: Pilot Project. Selecting a non-critical component or service for initial refactoring allows the team to gain hands-on experience with serverless technologies and identify potential challenges. This phase should be treated as a learning opportunity.
- Phase 2: Incremental Refactoring. Once the team is comfortable, subsequent phases involve refactoring additional components in manageable increments. Each increment should be well-defined and independently testable. This approach reduces the blast radius of potential issues.
- Phase 3: Integration and Testing. After each phase of refactoring, thorough integration testing is essential to ensure that the newly serverless components interact correctly with existing systems. This stage helps uncover any compatibility issues.
- Phase 4: Production Deployment. Once testing is complete and successful, the refactored components can be deployed to a production environment. This should be done gradually, monitoring performance and stability closely.
- Phase 5: Optimization and Iteration. Post-deployment, the serverless components should be continuously monitored and optimized. This includes performance tuning, cost optimization, and implementing new features.
Organizing a Plan for Prioritizing Component Refactoring
Prioritizing which components to refactor first is essential for maximizing the benefits of serverless adoption and minimizing disruption. This prioritization should be based on a set of objective criteria.
Factors to consider when prioritizing components for refactoring:
- Business Value. Prioritize components that deliver the most significant business value, such as those involved in core business processes or customer-facing applications. Refactoring these components first can yield rapid returns on investment.
- Complexity. Start with less complex components to gain experience and build confidence. Complex components should be refactored later, after the team has developed expertise.
- Dependencies. Identify and address dependencies between components. Refactor components with fewer dependencies first to minimize the impact on other parts of the application.
- Cost Savings Potential. Consider the potential cost savings associated with each component. Serverless technologies often offer significant cost reductions, especially for applications with variable workloads.
- Technical Debt. Address components with high technical debt. Refactoring these components can improve code quality, maintainability, and reduce operational overhead.
- Team Skillset. Leverage the team’s existing skillset. Prioritize components that align with the team’s expertise to accelerate the refactoring process.
Creating a Decision Tree for Selecting Appropriate Serverless Services
Selecting the appropriate serverless services is a critical step in the refactoring process. A decision tree can provide a structured approach to guide service selection, ensuring the optimal choice based on specific requirements.
The decision tree should incorporate the following criteria:
- Functionality Requirements. What specific tasks or functions does the component need to perform? This determines the need for services like AWS Lambda, Azure Functions, or Google Cloud Functions.
- Concurrency Requirements. How many concurrent requests will the component handle? This influences the choice of services and the need for auto-scaling capabilities.
- Data Storage Requirements. Does the component require data storage? If so, what type of data storage is needed (e.g., object storage, relational database, NoSQL database)? This will drive the selection of services like AWS S3, Azure Blob Storage, Google Cloud Storage, AWS DynamoDB, Azure Cosmos DB, or Google Cloud Datastore.
- Event-Driven Architecture. Does the component need to react to events? If so, consider services like AWS EventBridge, Azure Event Grid, or Google Cloud Pub/Sub.
- Integration Requirements. Does the component need to integrate with other services or systems? This may influence the choice of services based on their integration capabilities.
- Cost Considerations. What is the budget for the component? Consider the pricing models of different serverless services, including pay-per-use pricing, and factor in potential cost savings.
- Security Requirements. What security measures are required? Ensure the chosen services meet the necessary security standards, including authentication, authorization, and data encryption.
- Monitoring and Logging. What are the monitoring and logging requirements? Consider the availability of monitoring tools and logging capabilities for each service.
Decoupling Monolithic Applications
Decoupling a monolithic application is a crucial step in serverless refactoring. This process transforms a single, tightly-coupled codebase into a collection of independent, smaller services that can be deployed, scaled, and maintained independently. This modular approach enhances agility, resilience, and scalability, key benefits of embracing serverless architecture.
Strategies for Breaking Down a Monolithic Application
Breaking down a monolith requires careful planning and execution. Several strategies can be employed, each with its own advantages and disadvantages, depending on the application’s complexity and the desired level of decomposition.
- Strangler Fig Pattern: This pattern involves gradually replacing parts of the monolith with new serverless services. New features are implemented as serverless functions, and the existing monolith is progressively “strangled” or replaced. The original application continues to function while the new components are integrated. This approach minimizes risk and allows for incremental deployments.
- Vertical Slice Decomposition: This strategy involves dividing the monolith along functional boundaries, creating self-contained “slices” that encompass all aspects of a specific feature. Each slice, representing a specific business capability, can then be refactored into its own serverless service. This is an effective way to focus on specific areas and reduce the overall complexity of the application.
- Service Extraction: Identifying specific functionalities within the monolith that can be extracted and developed as independent services is essential. This approach involves identifying the core functionalities and creating new, separate serverless services. This is usually a more aggressive approach and can require significant refactoring of the original code.
Techniques for Identifying Service Boundaries and Responsibilities
Defining appropriate service boundaries is critical for successful decoupling. Poorly defined boundaries can lead to tight coupling between services, negating the benefits of serverless architecture. Several techniques can help identify the optimal boundaries and assign responsibilities.
- Domain-Driven Design (DDD): DDD principles help identify the core domain concepts and their relationships within the application. These concepts can then be mapped to serverless services, each responsible for a specific domain. This approach ensures that services are aligned with business needs and maintain high cohesion.
- Identifying Business Capabilities: Focus on identifying the core business capabilities the application provides. Each capability can be a candidate for a separate service. For example, an e-commerce application might have separate services for “product catalog,” “order processing,” and “payment gateway.”
- Analyzing Data Dependencies: Examining how data is accessed and modified within the monolith helps identify potential service boundaries. Services should ideally own their data and provide APIs for accessing and manipulating it. This promotes loose coupling and allows services to evolve independently.
- Using the “Single Responsibility Principle”: Each service should have a single, well-defined responsibility. This makes the service easier to understand, maintain, and scale. A service should ideally focus on a single business capability or a set of closely related functionalities.
Methods for Using APIs to Facilitate Communication Between Serverless Components
Once services are decoupled, they need to communicate with each other to perform their functions. APIs are the primary mechanism for this communication in a serverless environment. Well-designed APIs ensure that services can interact without tight coupling, promoting flexibility and scalability.
- RESTful APIs: Representational State Transfer (REST) APIs are a common choice for serverless applications. They use standard HTTP methods (GET, POST, PUT, DELETE) to interact with resources, making them easy to understand and implement. APIs should be well-documented, using standards like OpenAPI (formerly Swagger), to enable easy consumption by other services and clients.
- Asynchronous Communication: Implementing asynchronous communication using message queues (e.g., Amazon SQS, Google Cloud Pub/Sub) or event buses (e.g., Amazon EventBridge) is crucial for serverless applications. This allows services to communicate without blocking each other, improving responsiveness and scalability.
- API Gateways: API gateways (e.g., Amazon API Gateway, Google Cloud API Gateway) provide a central point of entry for all API requests. They handle tasks such as authentication, authorization, rate limiting, and request transformation. Using an API gateway simplifies the management and security of serverless APIs.
- Contract Testing: Contract testing ensures that the APIs adhere to the agreed-upon contracts between services. This helps prevent breaking changes and ensures that services can continue to communicate effectively as they evolve. Tools like Pact can be used for contract testing.
Data Migration and Management
Data migration and management are critical phases in serverless refactoring. Successfully transitioning data from existing infrastructure to serverless-compatible solutions is paramount for ensuring application functionality, performance, and scalability. This section explores the procedures, strategies, and services involved in effectively managing data during and after the refactoring process.
Procedures for Migrating Data
Migrating data to serverless environments requires a well-defined process to minimize downtime and data loss. This involves a series of steps, each with its own considerations.
- Assessment and Planning: Begin by thoroughly assessing the existing data infrastructure. This includes identifying the data sources, their size, schema, and dependencies. Planning involves selecting the target serverless data storage solutions (e.g., Amazon DynamoDB, Google Cloud Firestore, Azure Cosmos DB) that best suit the application’s needs. Consider factors like data access patterns, consistency requirements, and scalability demands.
- Data Extraction: Extract data from the source databases. This can be achieved using various methods, including:
- Batch Extraction: Suitable for large datasets, involves extracting data in bulk, typically using tools like AWS Data Migration Service (DMS), Google Cloud Dataflow, or Azure Data Factory. This approach often utilizes offline processing, which can be time-consuming.
- Incremental Extraction: For continuously updated data, implement change data capture (CDC) mechanisms to track changes in the source database and replicate them to the serverless storage in near real-time.
- Data Transformation: Transform the extracted data to match the schema and format of the serverless storage solution. This may involve data cleansing, type conversions, and schema mapping. Serverless functions (e.g., AWS Lambda, Google Cloud Functions, Azure Functions) can be employed for data transformation tasks.
- Data Loading: Load the transformed data into the target serverless database. Optimize the loading process to maximize performance and minimize downtime. Strategies include:
- Parallel Loading: Distribute the loading process across multiple workers or processes to speed up the transfer.
- Batching: Group data records into batches for efficient writing to the serverless storage.
- Verification and Validation: After the data is loaded, verify its integrity and accuracy. Compare the data in the serverless storage with the source data to ensure consistency. Implement validation checks to identify and correct any discrepancies.
- Cutover: Finally, switch the application to use the serverless data storage. This can be done gradually (e.g., using a canary release) or all at once, depending on the application’s requirements and risk tolerance.
Strategies for Managing Data Consistency and Integrity
Maintaining data consistency and integrity during the refactoring process is crucial. Several strategies help ensure data reliability and prevent data loss or corruption.
- Transactions: Employ transactions to ensure that data changes are atomic. In serverless environments, this can be achieved using transaction capabilities offered by the serverless databases. For instance, DynamoDB provides transaction support for multiple item operations within a single table or across multiple tables.
- Idempotency: Design operations to be idempotent, meaning that performing the same operation multiple times has the same effect as performing it once. This helps prevent data corruption due to retries or failures during the migration process.
- Versioning: Implement data versioning to track changes to data over time. This allows for data rollback in case of errors or data corruption. Serverless databases often provide built-in versioning features or support for integrating with version control systems.
- Auditing: Implement auditing to track all data changes, including who made the change, when it was made, and what data was modified. This provides valuable insights into data access patterns and helps in troubleshooting data-related issues.
- Data Validation: Implement robust data validation at both the application and database levels to ensure that only valid data is stored. This helps prevent data corruption and ensures data integrity. Use data validation frameworks or libraries to simplify the validation process.
- Monitoring and Alerting: Implement comprehensive monitoring and alerting to detect data inconsistencies, errors, or performance issues. Set up alerts to notify relevant stakeholders when anomalies are detected. Use monitoring tools to track data migration progress, data consistency, and data access patterns.
Serverless Databases and Data Services
Serverless databases and data services are designed to automatically scale and manage resources, eliminating the need for manual provisioning and management.
- Amazon DynamoDB: A NoSQL database that provides high performance, scalability, and availability. DynamoDB is well-suited for applications with high read/write demands and complex data models. It supports features such as automatic scaling, on-demand capacity mode, and transactions.
- Google Cloud Firestore: A NoSQL document database that offers real-time synchronization, offline support, and automatic scaling. Firestore is designed for mobile and web applications that require real-time data updates and a flexible data model.
- Azure Cosmos DB: A globally distributed, multi-model database that supports various data models, including document, graph, key-value, and column-family. Cosmos DB offers high performance, scalability, and availability, making it suitable for a wide range of applications.
- AWS Aurora Serverless: A MySQL and PostgreSQL-compatible relational database that automatically scales compute capacity based on application needs. Aurora Serverless eliminates the need to provision and manage database instances.
- Data Lake Services: Serverless data lake services, such as AWS S3, Google Cloud Storage, and Azure Data Lake Storage, provide scalable and cost-effective storage for large datasets. These services support various data formats and are often used for data warehousing and analytics.
- Data Integration Services: Serverless data integration services, such as AWS Glue, Google Cloud Dataflow, and Azure Data Factory, enable the automated extraction, transformation, and loading (ETL) of data from various sources. These services simplify the data integration process and reduce the need for manual coding.
Implementing Serverless Functions
The core of serverless refactoring lies in the implementation of serverless functions. These functions, often small and single-purpose, encapsulate specific pieces of application logic and are triggered by various events. This section details the process of writing, deploying, and integrating these functions within an event-driven architecture, along with code examples demonstrating common serverless tasks.
Writing and Deploying Serverless Functions
Serverless functions are typically written in languages like Python, Node.js, Java, or Go. The choice of language often depends on team expertise and the specific requirements of the task. Deployment involves packaging the function code along with any dependencies and configuring it to run on a serverless platform.Here’s a breakdown of the process:
- Code Development: Write the function code. This typically involves defining an entry point, handling input, and producing output. For example, a Python function might take a JSON payload as input, process it, and return a JSON response.
- Dependency Management: Include necessary libraries and dependencies in the deployment package. Most serverless platforms provide mechanisms for managing dependencies, such as `requirements.txt` for Python or `package.json` for Node.js.
- Configuration: Configure the function, specifying its memory allocation, timeout settings, and any environment variables it requires. This configuration is often done through a platform’s web console or a configuration file.
- Deployment: Deploy the function to the serverless platform. This process uploads the code and configuration to the platform’s infrastructure. The platform then handles scaling, execution, and monitoring.
Example (Python function):“`pythonimport jsondef handler(event, context): “”” This function receives a JSON event, processes it, and returns a response. “”” try: body = json.loads(event.get(‘body’, ”)) name = body.get(‘name’, ‘World’) except json.JSONDecodeError: return ‘statusCode’: 400, ‘body’: json.dumps(‘message’: ‘Invalid JSON payload’) response = ‘statusCode’: 200, ‘body’: json.dumps(‘message’: f’Hello, name!’) return response“`This function, when deployed, could be triggered by an HTTP request.
The `event` parameter contains information about the request, including the request body. The `context` parameter provides information about the execution environment. The function parses the request body (assumed to be JSON), extracts a `name` parameter, and returns a greeting.
Event-Driven Architectures and Function Triggering
Serverless functions are most effective when integrated into an event-driven architecture. This architecture uses events as triggers to initiate function execution. Events can originate from various sources, such as HTTP requests, database changes, file uploads, or scheduled tasks.The following illustrates how an event-driven architecture works:
- Event Source: An event source, such as an API Gateway, a database, or an object storage service, generates an event.
- Event Bus (Optional): An event bus, such as Amazon EventBridge or Azure Event Grid, can be used to route events to the appropriate functions. This allows for decoupling event sources from function consumers.
- Function Trigger: A trigger is configured to listen for specific events. When an event matching the trigger criteria occurs, the function is invoked.
- Function Execution: The serverless function executes, processing the event data and performing its designated task.
Examples of event triggers:
- HTTP Requests: An API Gateway can trigger a function when an HTTP request is received.
- Database Updates: A database trigger can invoke a function when data is inserted, updated, or deleted in a table.
- File Uploads: An object storage service can trigger a function when a file is uploaded.
- Scheduled Tasks: A scheduler can trigger a function at predefined intervals.
Code Snippets for Common Serverless Function Tasks
Below are code snippets illustrating common serverless function tasks. These examples use Python, but the principles apply to other languages as well.
- Data Processing:
“`pythonimport jsondef process_data(event, context): “”” Processes data received in an event. “”” try: data = json.loads(event[‘body’]) processed_data = process_logic(data) # Replace with your processing logic return ‘statusCode’: 200, ‘body’: json.dumps(processed_data) except Exception as e: return ‘statusCode’: 500, ‘body’: json.dumps(‘error’: str(e)) def process_logic(data): “”” Placeholder for your data processing logic.
“”” # Example: Calculate the sum of a list of numbers if isinstance(data, list): return ‘sum’: sum(data) else: return ‘message’: ‘Input must be a list’“`This function receives data, presumably in JSON format, from an event, performs processing (represented by `process_logic`), and returns the result.
- Database Interaction (Read):
“`pythonimport jsonimport boto3 # Example for AWS, use appropriate SDK for other platformsdef get_data_from_db(event, context): “”” Retrieves data from a database. “”” table_name = ‘your_table_name’ item_id = event[‘pathParameters’][‘id’] # Assuming ID is passed as a path parameter dynamodb = boto3.resource(‘dynamodb’) table = dynamodb.Table(table_name) try: response = table.get_item( Key= ‘id’: item_id ) item = response.get(‘Item’) if item: return ‘statusCode’: 200, ‘body’: json.dumps(item) else: return ‘statusCode’: 404, ‘body’: json.dumps(‘message’: ‘Item not found’) except Exception as e: return ‘statusCode’: 500, ‘body’: json.dumps(‘error’: str(e)) “`This function reads data from a database (DynamoDB in this example).
It retrieves an item based on an ID passed in the event. It uses the AWS SDK (Boto3). Adapting the database interaction code to other platforms requires the respective SDK and connection details.
- Database Interaction (Write):
“`pythonimport jsonimport boto3 # Example for AWSdef write_data_to_db(event, context): “”” Writes data to a database. “”” table_name = ‘your_table_name’ try: body = json.loads(event[‘body’]) dynamodb = boto3.resource(‘dynamodb’) table = dynamodb.Table(table_name) response = table.put_item( Item=body ) return ‘statusCode’: 200, ‘body’: json.dumps(‘message’: ‘Item added successfully’) except Exception as e: return ‘statusCode’: 500, ‘body’: json.dumps(‘error’: str(e)) “`This function writes data to a database (DynamoDB).
It expects data in the event’s body, parses it as JSON, and inserts it into the specified table.
- File Processing:
“`pythonimport jsonimport boto3 # Example for AWSdef process_file(event, context): “”” Processes a file uploaded to an object storage service. “”” bucket_name = event[‘Records’][0][‘s3’][‘bucket’][‘name’] file_key = event[‘Records’][0][‘s3’][‘object’][‘key’] s3 = boto3.client(‘s3’) try: # Download the file file_object = s3.get_object(Bucket=bucket_name, Key=file_key) file_content = file_object[‘Body’].read().decode(‘utf-8′) # Assuming text file # Process the file content processed_content = process_file_content(file_content) # Example: Upload the processed content to another bucket # s3.put_object(Bucket=’processed-bucket’, Key=file_key, Body=processed_content) return ‘statusCode’: 200, ‘body’: json.dumps(‘message’: ‘File processed successfully’) except Exception as e: return ‘statusCode’: 500, ‘body’: json.dumps(‘error’: str(e)) def process_file_content(content): “”” Placeholder for your file processing logic.
“”” # Example: Count the number of lines in the file lines = content.splitlines() return ‘line_count’: len(lines)“`This function is triggered by an object storage event (e.g., a file upload to S3). It downloads the file, processes its content (using the `process_file_content` function), and can perform actions based on the processed content, like uploading it to another location.These examples demonstrate fundamental serverless function tasks.
The specific implementation details will vary based on the serverless platform, the chosen programming language, and the nature of the task. However, the core principles of event handling, data processing, and integration with other services remain consistent.
API Gateway Integration
Integrating serverless functions with an API gateway is a critical step in serverless refactoring. This integration allows for external access to the functionality encapsulated within the serverless functions, providing a unified entry point, managing API traffic, and enforcing security policies. The API gateway acts as the front door to your serverless backend, abstracting the underlying complexity and enabling scalability and maintainability.
Integrating Serverless Functions with an API Gateway
The integration process typically involves configuring the API gateway to route incoming requests to the appropriate serverless functions. This configuration defines the API endpoints, the HTTP methods supported, and the function to be invoked.
- Endpoint Configuration: Each API endpoint represents a specific action or resource accessible through the serverless functions. The API gateway allows defining the URL path (e.g., `/users`, `/products/id`) and the HTTP method (GET, POST, PUT, DELETE) for each endpoint. For example, a GET request to `/users` might trigger a serverless function to retrieve a list of users from a database.
- Function Mapping: The API gateway maps each endpoint to the corresponding serverless function. This mapping specifies which function should be executed when a request is received at a particular endpoint. This is often achieved through configuration settings in the API gateway’s management console or through Infrastructure as Code (IaC) tools.
- Request Transformation: The API gateway can transform incoming requests before they reach the serverless functions. This might involve converting request parameters, adding headers, or modifying the request body. For example, the gateway can parse and validate JSON payloads before passing them to the function.
- Response Transformation: Similarly, the API gateway can transform the responses from the serverless functions before returning them to the client. This could involve formatting the response, adding headers, or applying content type negotiation.
Designing API Endpoint Configuration, Routing, and Security
Designing an effective API gateway configuration requires careful consideration of endpoint design, routing strategies, and security measures. A well-designed configuration ensures that the API is easy to use, secure, and scalable.
- Endpoint Design: API endpoints should be designed with RESTful principles in mind, using clear and concise URL paths that reflect the resources and actions being performed. Use nouns for resources and verbs (using HTTP methods) for actions. For example, use `/users/userId` to represent a user with a specific ID, using GET to retrieve the user, PUT to update, and DELETE to remove.
Consider using API versioning (e.g., `/v1/users`) to allow for backward compatibility when making changes to the API.
- Routing Strategies: The API gateway routes requests to the appropriate serverless functions based on the configured endpoints and routing rules. For more complex applications, routing strategies might involve path-based routing, header-based routing, or parameter-based routing. For example, path-based routing could direct requests to different functions based on the URL path (e.g., `/products` to a product listing function, `/products/id` to a product detail function).
Header-based routing can use headers to route requests to different functions based on the client’s request headers (e.g., `X-API-Version: v2`).
- Security Measures: API security is paramount. The API gateway provides several security features to protect the serverless functions from unauthorized access.
- Authentication: Verify the identity of the client making the request. This can involve using API keys, OAuth 2.0, or JWT (JSON Web Tokens).
- Authorization: Determine whether the authenticated client is authorized to access the requested resource. This can involve role-based access control (RBAC) or attribute-based access control (ABAC).
- Rate Limiting: Protect against abuse by limiting the number of requests from a specific client within a given time period.
- Input Validation: Validate the data in the request to prevent malicious attacks.
- Encryption: Use HTTPS to encrypt all communication between the client and the API gateway.
Handling API Authentication and Authorization Techniques
Implementing robust authentication and authorization mechanisms is crucial for securing serverless APIs. Several techniques are available, each with its strengths and weaknesses.
- API Keys: A simple method for authentication, where each client is assigned a unique API key. The API key is included in the request header (e.g., `X-API-Key: YOUR_API_KEY`). API keys are easy to implement but less secure than other methods, as they can be easily compromised.
- OAuth 2.0: A widely used standard for delegated authorization. Clients obtain an access token from an authorization server (e.g., Google, Facebook, or a custom authorization server). The access token is then used to authenticate and authorize requests to the API gateway. OAuth 2.0 provides a more secure and flexible authentication and authorization model.
- JSON Web Tokens (JWT): A compact and self-contained way to represent claims securely between two parties. JWTs are commonly used for authentication and authorization in serverless applications. The serverless function can verify the JWT’s signature and extract claims (e.g., user ID, roles) to authorize access to resources. For example, a JWT might be issued by an identity provider (IdP) and included in the `Authorization` header (e.g., `Bearer
`). The serverless function would then decode and validate the JWT to determine the user’s identity and permissions. - IAM Roles (for AWS): In the AWS ecosystem, IAM roles can be used to grant access to serverless functions. The API gateway can be configured to assume an IAM role on behalf of the client. This allows the function to access AWS resources (e.g., databases, storage) without requiring the client to manage credentials.
Monitoring and Observability
Effective monitoring and observability are crucial for the operational success of serverless applications. Unlike traditional infrastructure, serverless environments require a shift in perspective, focusing on the performance of individual functions and the interactions between them. This shift necessitates a robust system for collecting, analyzing, and visualizing data to identify performance bottlenecks, security vulnerabilities, and potential issues before they impact users.
A well-implemented monitoring strategy provides insights into the application’s health, allowing for proactive troubleshooting and optimization.
Identifying Key Metrics
Defining the correct metrics to monitor is paramount to understanding the behavior of a serverless application. These metrics should be chosen based on the specific functionality of the application and its critical business requirements. The selected metrics should be categorized into performance, error, and resource consumption areas.
- Performance Metrics: These metrics gauge the speed and responsiveness of the application.
- Invocation Count: The number of times a function is executed. This metric provides insight into the function’s usage and load.
- Duration: The time it takes for a function to complete execution, measured in milliseconds or seconds. High duration values can indicate performance bottlenecks or inefficient code.
- Cold Start Duration: The time taken for a function’s first execution after being idle. Serverless platforms often spin down instances to save resources, and a cold start can introduce latency.
- Concurrent Executions: The number of function instances running simultaneously. This metric helps assess the application’s ability to handle concurrent requests.
- Latency: The time it takes for a request to be processed and a response to be returned. Latency is critical for user experience.
- Error Metrics: Tracking errors is essential for identifying and resolving issues within the application.
- Error Count: The total number of errors encountered during function execution. A high error count signals the presence of bugs or configuration problems.
- Error Rate: The percentage of function invocations that result in errors. This metric provides a normalized view of the application’s error performance.
- Error Types: The categorization of errors by type (e.g., timeout, internal server error, bad request). Understanding error types helps prioritize debugging efforts.
- Resource Consumption Metrics: Monitoring resource consumption helps optimize cost and ensure the application is operating efficiently.
- Memory Usage: The amount of memory consumed by a function during execution. Excessive memory usage can lead to performance degradation and increased costs.
- CPU Utilization: The percentage of CPU resources utilized by a function. High CPU utilization may indicate performance bottlenecks or inefficient code.
- Data Transfer: The amount of data transferred in and out of the application. Monitoring data transfer is critical for cost optimization, especially when dealing with large files or high traffic.
- Storage Usage: The amount of storage used by the application, particularly important for stateful serverless applications that may store data in databases or object storage.
Implementing Logging, Tracing, and Alerting
Implementing robust logging, tracing, and alerting mechanisms is fundamental for serverless application observability. These mechanisms work together to provide a comprehensive view of the application’s behavior, enabling rapid identification and resolution of issues.
- Logging: Logging involves capturing events and messages generated by the application. Serverless functions should log detailed information about their execution, including input parameters, function calls, and error messages.
- Structured Logging: Use structured logging formats (e.g., JSON) to enable easier parsing and analysis of log data. Structured logs allow for efficient querying and filtering of log events.
- Log Aggregation: Centralize log data by aggregating logs from multiple functions and services into a single location. This enables a holistic view of the application’s behavior.
- Log Levels: Utilize different log levels (e.g., DEBUG, INFO, WARN, ERROR) to categorize log messages based on their severity. This helps prioritize and filter log events.
- Tracing: Tracing involves tracking the flow of requests through the application. It provides insights into the interactions between different functions and services.
- Distributed Tracing: Implement distributed tracing to track requests across multiple functions and services. This allows for end-to-end visibility into the application’s behavior.
- Span Context Propagation: Propagate trace context (e.g., trace IDs, span IDs) between functions to correlate events and understand the flow of requests.
- Tracing Tools: Utilize tracing tools (e.g., AWS X-Ray, Jaeger, Zipkin) to visualize traces and identify performance bottlenecks.
- Alerting: Alerting involves defining rules that trigger notifications when specific conditions are met.
- Metric-Based Alerts: Create alerts based on key metrics, such as error rates, latency, and resource consumption.
- Threshold-Based Alerts: Define thresholds for metrics, and trigger alerts when these thresholds are exceeded.
- Notification Channels: Configure notification channels (e.g., email, SMS, Slack) to receive alerts.
Creating a Dashboard for Visualizing Serverless Application Behavior
Visualizing serverless application behavior through a dashboard is essential for gaining insights into the application’s health and performance. A well-designed dashboard provides a centralized view of key metrics, enabling rapid identification of issues and trends.
- Dashboard Design Principles: Follow these principles when designing a dashboard.
- Clarity: The dashboard should be easy to understand and interpret.
- Relevance: Display only the most important metrics.
- Actionability: The dashboard should provide insights that can be used to take action.
- Customization: Allow users to customize the dashboard to meet their specific needs.
- Dashboard Components: Key components to include on a serverless application dashboard.
- Key Metrics: Display key metrics (e.g., invocation count, duration, error rate) using charts and graphs.
- Error Summary: Provide a summary of errors, including error types and error counts.
- Performance Charts: Visualize performance metrics (e.g., latency, cold start duration) using line charts and histograms.
- Resource Consumption: Display resource consumption metrics (e.g., memory usage, CPU utilization) using bar charts and gauges.
- Alert Status: Show the status of alerts, including active alerts and recent alert notifications.
- Log Search: Provide a way to search and filter log data directly from the dashboard.
- Dashboard Tools: Popular tools for creating serverless application dashboards.
- CloudWatch Dashboards (AWS): Integrate with CloudWatch to visualize metrics, logs, and alarms.
- Grafana: A versatile open-source platform for creating dashboards.
- Datadog: A comprehensive monitoring and analytics platform.
- New Relic: A monitoring and observability platform.
Testing Serverless Applications
Testing serverless applications necessitates a shift in perspective compared to traditional monolithic applications. The distributed nature of serverless architectures, with their event-driven interactions and reliance on external services, demands a comprehensive testing strategy. This strategy must encompass various testing levels to ensure the reliability, performance, and security of the application. The focus should be on isolating components, simulating environments, and automating tests to provide rapid feedback and facilitate continuous integration and continuous deployment (CI/CD) pipelines.
Testing Methodologies for Serverless Components
A robust testing strategy for serverless applications incorporates multiple testing methodologies to cover different aspects of the application’s functionality and behavior. Each methodology plays a crucial role in ensuring code quality and overall system reliability.
- Unit Tests: Unit tests are fundamental for verifying the functionality of individual serverless functions. These tests isolate each function and its dependencies, ensuring that it behaves as expected given specific inputs. Mocking is extensively used to simulate external services and dependencies, such as databases, APIs, and event sources. This allows for focused testing without the overhead of deploying the entire application or interacting with live services.
For example, consider a serverless function designed to process user registration data. A unit test would verify that, given valid input data (e.g., username, email, password), the function correctly validates the data, encrypts the password, and stores the user information in a database. Mocking the database interaction allows the test to focus solely on the function’s logic, ensuring it behaves correctly.
- Integration Tests: Integration tests verify the interactions between different serverless components and external services. They ensure that the various parts of the application work together seamlessly. This testing level involves deploying a subset of the application components and testing their interactions in a more realistic environment. For example, an integration test might verify that an API Gateway correctly routes requests to a specific serverless function, which then retrieves data from a database and returns it to the client.
An example could be testing the communication between an API Gateway and a Lambda function. The test would simulate an HTTP request to the API Gateway, verifying that the request is correctly routed to the Lambda function, the function processes the request (e.g., retrieves data from a database), and the API Gateway returns the correct response to the client.
- End-to-End (E2E) Tests: End-to-end tests validate the entire application workflow from the user’s perspective. These tests simulate real-world user interactions, verifying that the application functions as expected across all components and services. E2E tests often involve deploying the entire application stack and testing it against a production-like environment. These tests are crucial for ensuring that the application meets its business requirements and provides a positive user experience.
For instance, an e2e test for an e-commerce application might simulate a user browsing products, adding items to a cart, proceeding to checkout, and completing a purchase. The test would verify that the user can successfully navigate the application, add items to the cart, enter payment information, and receive a confirmation email. This type of testing validates that all serverless functions, API Gateways, databases, and other services work correctly together to fulfill the user’s request.
Simulating Serverless Environments for Testing Purposes
Simulating serverless environments is essential for efficient and effective testing. It allows developers to test their applications without incurring the costs and complexities associated with deploying to a fully managed serverless environment every time a test is run. Several techniques and tools facilitate the simulation of serverless environments.
- Local Development and Testing Frameworks: Tools like AWS SAM (Serverless Application Model) and Serverless Framework provide local emulators for serverless components, enabling developers to run and test their functions locally. These emulators mimic the behavior of AWS services, such as Lambda, API Gateway, and DynamoDB, allowing developers to test their functions and application logic without deploying to the cloud. This accelerates the development cycle and reduces costs.
For example, using AWS SAM, developers can define their serverless application in a YAML template, which includes function definitions, API Gateway configurations, and other resources. The SAM CLI can then be used to deploy the application locally, allowing developers to test their functions using the same infrastructure as they would in the cloud.
- Mocking and Stubbing: Mocking and stubbing are crucial for isolating components and simulating dependencies. Mocking involves creating fake implementations of external services, such as databases, APIs, and event sources. This allows developers to control the behavior of these dependencies and test their functions in isolation. Stubbing provides pre-defined responses or behaviors for external services, allowing developers to simulate various scenarios and test their functions accordingly.
For instance, when testing a Lambda function that interacts with a database, a mock database can be created to simulate the database’s behavior. The mock database would allow developers to define specific responses for database queries, enabling them to test different scenarios, such as successful data retrieval, data not found, or database errors.
- Containerization: Containerization technologies, such as Docker, can be used to package serverless functions and their dependencies into isolated environments. This ensures consistency across different testing environments and simplifies the deployment process. Docker containers can also be used to simulate external services, such as databases and message queues, providing a controlled and reproducible testing environment.
A practical illustration is packaging a Lambda function, along with its dependencies, within a Docker container.
The container can then be deployed to a local environment or a CI/CD pipeline, ensuring that the function behaves consistently across different environments. This approach facilitates the testing of complex dependencies and reduces the risk of environment-specific issues.
Organizing a Testing Framework for Serverless Applications
A well-organized testing framework is essential for managing and automating tests in serverless applications. This framework should include a structured approach to test execution, reporting, and continuous integration.
- Test Automation: Automation is paramount for efficient testing. Tests should be automated and integrated into the CI/CD pipeline to provide rapid feedback and ensure that code changes do not introduce regressions. Automation tools can execute tests, generate reports, and notify developers of any failures. This enables developers to identify and fix issues early in the development cycle.
For example, integrating unit tests and integration tests into a CI/CD pipeline.
When a developer commits code changes, the pipeline automatically triggers the execution of the tests. If any tests fail, the pipeline stops, and the developer receives a notification, allowing them to address the issue promptly.
- Test Reporting: Comprehensive test reporting is crucial for tracking test results and identifying areas for improvement. Reports should include test results, code coverage metrics, and failure analysis. These reports provide insights into the quality of the application and help developers to prioritize their testing efforts.
A practical example would be generating a test report after each build in the CI/CD pipeline.
The report would include details such as the number of tests run, the number of tests passed, the number of tests failed, and the code coverage percentage. This information can be used to track the progress of testing and identify any areas that require more attention.
- Continuous Integration and Continuous Delivery (CI/CD): Integrating tests into a CI/CD pipeline is essential for automating the build, test, and deployment processes. This enables developers to release new features and bug fixes quickly and reliably. CI/CD pipelines automatically execute tests, deploy code changes, and provide feedback to developers.
An example is a CI/CD pipeline that automatically builds, tests, and deploys a serverless application.
The pipeline would start with a code commit, trigger a build process, execute unit tests and integration tests, and deploy the application to a staging environment. If all tests pass, the pipeline would then deploy the application to a production environment. This automated process ensures that code changes are thoroughly tested and deployed in a consistent and reliable manner.
Deployment and CI/CD Pipelines
The deployment of serverless applications and the establishment of robust CI/CD pipelines are critical components of a successful serverless refactoring initiative. These processes ensure the rapid, reliable, and automated delivery of code changes, enabling faster iteration cycles and improved application stability. Efficient deployment strategies, coupled with automated pipelines, are essential for realizing the benefits of serverless architectures, such as scalability, cost optimization, and reduced operational overhead.
Process of Deploying Serverless Applications
Deploying serverless applications involves several distinct steps, each requiring careful consideration to ensure a smooth and successful release. The process leverages the capabilities of cloud providers to handle the underlying infrastructure, allowing developers to focus on code and business logic.
- Code Packaging and Preparation: This initial step involves preparing the application code for deployment. Serverless functions are typically packaged as ZIP files or container images. Dependencies are included, and the code is structured to align with the specific serverless platform’s requirements (e.g., AWS Lambda, Azure Functions, Google Cloud Functions).
- Infrastructure Definition: Serverless applications often rely on various cloud resources, such as API Gateways, databases, and storage buckets. These resources are typically defined using Infrastructure as Code (IaC) tools, such as AWS CloudFormation, Azure Resource Manager templates, or Terraform. This approach enables consistent and repeatable deployments.
- Deployment to the Cloud Provider: The prepared code and infrastructure definitions are then deployed to the chosen cloud provider. This is usually accomplished using command-line interfaces (CLIs), SDKs, or deployment tools provided by the cloud provider. The deployment process automatically provisions and configures the necessary resources.
- Configuration and Environment Variables: Serverless applications often require configuration settings and environment variables to manage sensitive data, such as API keys and database connection strings. These settings are typically managed within the cloud provider’s platform, allowing for secure and centralized configuration.
- Testing and Validation: After deployment, the application undergoes testing and validation to ensure it functions correctly. This includes unit tests, integration tests, and potentially end-to-end tests. Monitoring and logging are also set up to provide insights into application performance and identify potential issues.
Designing CI/CD Pipelines for Automation
Implementing CI/CD pipelines is crucial for automating the build, test, and deployment processes of serverless applications. This automation streamlines the development workflow, reduces the risk of errors, and accelerates the release cycle. A well-designed pipeline integrates seamlessly with the development process, providing continuous feedback and ensuring code quality.
- Source Code Management: The CI/CD pipeline begins with a source code repository (e.g., Git). Developers commit code changes to the repository, triggering the pipeline.
- Build Stage: In this stage, the code is compiled, dependencies are installed, and the application is packaged for deployment. Build tools specific to the programming language and serverless platform are used.
- Testing Stage: Automated tests, including unit tests, integration tests, and potentially performance tests, are executed to validate the code changes. Test results are analyzed to identify any failures or issues.
- Deployment Stage: If all tests pass, the application is deployed to a staging or production environment. The deployment process uses IaC tools to provision and configure the necessary cloud resources.
- Monitoring and Feedback: After deployment, the application is monitored for performance and stability. Logs and metrics are collected and analyzed to identify potential issues. Feedback from the monitoring system can trigger automated rollbacks or other corrective actions.
Best Practices for Managing Infrastructure as Code
Infrastructure as Code (IaC) is a fundamental practice for managing serverless infrastructure. IaC enables the definition and management of infrastructure resources through code, promoting consistency, repeatability, and automation. Several best practices are essential for effectively utilizing IaC in serverless deployments.
- Choose the Right Tool: Select an IaC tool that aligns with the cloud provider and the project’s requirements. Popular choices include AWS CloudFormation, Terraform, Azure Resource Manager templates, and Google Cloud Deployment Manager.
- Modularize Infrastructure Definitions: Break down infrastructure definitions into modular components to improve reusability and maintainability. This approach makes it easier to manage complex infrastructure configurations.
- Version Control Infrastructure Code: Store IaC code in a version control system (e.g., Git) to track changes, collaborate effectively, and enable rollbacks.
- Automate Infrastructure Deployments: Integrate IaC code into the CI/CD pipeline to automate infrastructure deployments. This ensures that infrastructure changes are deployed consistently and reliably.
- Test Infrastructure Code: Implement testing strategies for IaC code to validate the correctness of infrastructure configurations. This helps to prevent errors and ensure that the infrastructure behaves as expected.
- Follow Security Best Practices: Implement security best practices in IaC code, such as using least privilege principles, managing secrets securely, and regularly reviewing infrastructure configurations for security vulnerabilities. For example, utilize features like AWS Secrets Manager to manage sensitive data, preventing hardcoding credentials directly in IaC templates.
Outcome Summary
In conclusion, refactoring for serverless is a multifaceted endeavor that, when executed strategically, unlocks significant benefits in terms of cost, scalability, and developer productivity. By carefully assessing your application, defining a phased refactoring strategy, and leveraging the power of serverless services, you can modernize your infrastructure and position your applications for future growth. The principles Artikeld here provide a robust foundation for successful serverless adoption, enabling organizations to build more resilient, efficient, and scalable software solutions.
Key Questions Answered
What are the primary drivers for serverless refactoring?
The primary drivers include cost optimization (pay-per-use model), improved scalability (automatic scaling), enhanced developer productivity (focus on code, not infrastructure), and increased agility (faster deployment cycles).
How does serverless impact application security?
Serverless can improve security by reducing the attack surface (less infrastructure to manage), providing automatic security updates, and offering built-in security features within serverless platforms. However, it requires careful attention to function security, API gateway configurations, and access control.
What are the key considerations when choosing a serverless platform (e.g., AWS, Azure, Google Cloud)?
Key considerations include pricing models, available services, platform maturity, integration capabilities with existing systems, and the skill set of your development team. Evaluate each platform’s strengths and weaknesses relative to your specific requirements.
How can I ensure data consistency during a serverless refactoring project?
Employ strategies such as transaction management, data synchronization mechanisms (e.g., event-driven architectures), and careful planning of data migration steps. Consider using serverless-compatible databases that offer consistency guarantees.
What are the best practices for monitoring and alerting in a serverless environment?
Implement comprehensive logging, tracing, and metrics collection. Set up alerts based on key performance indicators (KPIs) such as function invocation duration, error rates, and resource utilization. Utilize dashboards to visualize application behavior and identify potential issues.