Delving into the realm of serverless computing necessitates a thorough examination of the developer experience (DevEx). Serverless architectures, while promising scalability and cost efficiency, introduce unique challenges and opportunities for developers. This exploration investigates the nuances of building, deploying, and maintaining applications within a serverless framework, focusing on the tools, practices, and considerations that define a positive and productive DevEx.
This analysis will cover key aspects such as tooling, code development, monitoring, local development, security, collaboration, cost optimization, and framework utilization. We will dissect each element, providing insights into best practices and potential pitfalls. The ultimate goal is to equip developers with the knowledge necessary to navigate the complexities of serverless development and harness its full potential.
Understanding the Fundamentals of Serverless DevEx
The developer experience (DevEx) in serverless computing is a critical aspect of its adoption and success. A well-designed DevEx streamlines the development lifecycle, from code creation and testing to deployment and monitoring, ultimately improving developer productivity and satisfaction. This section will delve into the foundational principles of serverless DevEx, common challenges, and the distinctions between serverless and traditional development workflows.
Core Principles of a Positive Serverless Developer Experience
A positive serverless DevEx is built upon several key principles that aim to simplify and accelerate the development process. These principles prioritize developer efficiency, ease of use, and rapid iteration.
- Abstraction of Infrastructure: Serverless platforms manage the underlying infrastructure, allowing developers to focus solely on writing code. This abstraction removes the complexities of server provisioning, scaling, and maintenance. For example, developers can deploy a function without needing to configure servers, databases, or load balancers.
- Rapid Iteration and Feedback Loops: Serverless architectures enable faster development cycles due to their inherent scalability and automated deployment capabilities. Developers can quickly deploy and test code changes, receiving rapid feedback on their work. This fosters a more agile and iterative development process.
- Simplified Deployment and Management: Serverless platforms offer simplified deployment processes, often involving a few commands or clicks. Monitoring and logging are also streamlined, providing developers with readily available insights into the performance and health of their applications.
- Cost Optimization: Serverless computing operates on a pay-per-use model, where developers are charged only for the actual resources consumed. This can lead to significant cost savings compared to traditional infrastructure-based deployments, especially for applications with fluctuating workloads.
- Local Development and Testing: Effective serverless DevEx includes robust local development and testing capabilities. Developers should be able to simulate the serverless environment locally to test their code before deployment. This minimizes the risk of errors and speeds up the development process.
Common Challenges in Serverless Development
Despite its benefits, serverless development presents several challenges that can impact the developer experience. These challenges must be addressed to ensure a smooth and productive development workflow.
- Debugging and Troubleshooting: Debugging serverless applications can be more complex than debugging traditional applications. Distributed architectures and the ephemeral nature of serverless functions can make it difficult to trace errors and identify the root cause of issues. Effective logging and monitoring tools are essential for troubleshooting.
- Cold Starts: Serverless functions can experience “cold starts,” where the function’s execution environment needs to be initialized before the code can run. This can lead to latency issues, particularly for applications with infrequent usage. Strategies like pre-warming functions or using provisioned concurrency can mitigate this problem.
- Vendor Lock-in: Serverless platforms are often tied to specific cloud providers, which can lead to vendor lock-in. Migrating a serverless application from one provider to another can be a complex and time-consuming process. Using platform-agnostic tools and following architectural best practices can help mitigate this risk.
- Monitoring and Observability: Monitoring and observing serverless applications can be challenging due to their distributed and dynamic nature. Developers need access to comprehensive monitoring tools that provide insights into function performance, resource utilization, and error rates.
- Complexity of Distributed Systems: Serverless applications are often composed of multiple interconnected functions and services. Managing the complexity of these distributed systems can be challenging, requiring developers to understand the interactions between different components and how they impact overall application performance.
Key Differences Between Traditional and Serverless Development Workflows
Traditional and serverless development workflows differ significantly in several key aspects, impacting how developers approach building and deploying applications.
| Feature | Traditional Development | Serverless Development |
|---|---|---|
| Infrastructure Management | Developers manage servers, operating systems, and scaling. | Infrastructure is managed by the cloud provider. |
| Deployment | Complex deployment processes involving server configuration and application setup. | Simplified deployment, often with a few commands or clicks. |
| Scaling | Requires manual scaling or complex auto-scaling configurations. | Automatic scaling based on demand. |
| Cost Model | Fixed costs based on infrastructure usage, regardless of actual resource consumption. | Pay-per-use model, where developers are charged only for the resources consumed. |
| Development Cycle | Longer development cycles due to infrastructure management and deployment complexities. | Shorter development cycles due to simplified deployment and rapid feedback loops. |
| Debugging | Debugging is typically done on a dedicated environment. | Debugging can be complex, involving tracing across multiple functions and services. |
For instance, in traditional development, deploying a simple web application might involve setting up a virtual machine, installing a web server, configuring the application, and managing scaling. In contrast, serverless development would involve writing the application code and deploying it to a platform like AWS Lambda, where the infrastructure is automatically managed.
Serverless Tooling and Infrastructure

Serverless development relies heavily on robust tooling and a well-defined infrastructure to streamline the development lifecycle and enhance the developer experience. This section delves into the essential tools and infrastructural components that support serverless application development, highlighting their functionalities and impact on developer workflows.
Serverless Tooling
The following table presents a selection of popular serverless tooling, categorized by their primary functionalities and target use cases. The table aims to provide an overview of the available tools, their core features, and the scenarios where they are most beneficial for developers.
| Tool | Functionality | Target Use Cases | Examples |
|---|---|---|---|
| Serverless Framework | Deployment, orchestration, and management of serverless applications across multiple cloud providers. Supports CI/CD integration. | Multi-cloud deployments, Infrastructure-as-Code (IaC), application lifecycle management. | Deploying a Node.js application to AWS Lambda, Azure Functions, or Google Cloud Functions using a YAML configuration file. |
| AWS SAM (Serverless Application Model) | Simplifies the definition and deployment of serverless applications on AWS. Offers a local development environment. | Developing and deploying serverless applications specifically on AWS, testing locally before deployment. | Defining an API Gateway and Lambda function using SAM templates, testing the API locally using the SAM CLI. |
| Azure Functions Core Tools | Local development, debugging, and publishing of Azure Functions. Supports multiple languages. | Developing and testing Azure Functions locally, deploying functions to the Azure cloud. | Creating and debugging a Python-based Azure Function locally using the Azure Functions Core Tools CLI. |
| Google Cloud Functions Framework | Enables local development and testing of Google Cloud Functions. | Developing and testing Google Cloud Functions locally. | Writing a Go function and testing it locally using the Google Cloud Functions Framework. |
| Terraform | Infrastructure-as-Code tool for provisioning and managing cloud resources, including serverless components. | Automating infrastructure provisioning, managing complex serverless architectures across different cloud providers. | Provisioning an AWS Lambda function, an API Gateway, and a DynamoDB table using Terraform configuration files. |
Essential Infrastructure Components for Serverless Applications
Serverless applications rely on a set of core infrastructure components to function effectively. These components, often managed by the cloud provider, are crucial for the execution, storage, and networking aspects of serverless applications.
- Compute: This encompasses the execution environment where the serverless functions run. Examples include AWS Lambda functions, Azure Functions, and Google Cloud Functions. The compute component handles the allocation of resources (CPU, memory) and the execution of the function code in response to events.
- Storage: Storage components are necessary for persistent data storage and retrieval. This can include object storage (e.g., Amazon S3, Azure Blob Storage, Google Cloud Storage), databases (e.g., Amazon DynamoDB, Azure Cosmos DB, Google Cloud Firestore), and other storage solutions. The choice of storage depends on the specific needs of the application, such as data volume, access patterns, and data structure.
- Networking: Networking components manage the communication between serverless functions and other services, as well as external clients. This includes API gateways (e.g., Amazon API Gateway, Azure API Management, Google Cloud API Gateway), which act as entry points for API requests, and virtual networks that isolate and secure the functions.
- Event Sources: Event sources trigger the execution of serverless functions. These can be various services like HTTP requests (through API gateways), database changes (e.g., DynamoDB Streams, Azure Event Hubs, Google Cloud Pub/Sub), scheduled events (e.g., AWS CloudWatch Events, Azure Event Grid, Google Cloud Scheduler), and other events from cloud services.
- Monitoring and Logging: Monitoring and logging are essential for observing the performance and behavior of serverless applications. These components collect metrics (e.g., invocation count, execution time, errors) and logs to provide insights into the application’s health and identify potential issues. Tools include AWS CloudWatch, Azure Monitor, and Google Cloud Operations.
- Authentication and Authorization: Authentication and authorization mechanisms are critical for securing serverless applications. This involves verifying user identities and controlling access to resources. Cloud providers offer services like AWS Cognito, Azure Active Directory, and Google Cloud Identity Platform for managing user authentication and authorization.
Impact of Serverless Platforms on Developer Workflows
Different serverless platforms, such as AWS Lambda, Azure Functions, and Google Cloud Functions, influence developer workflows in distinct ways. These differences relate to the development environment, deployment process, supported programming languages, and the available tooling.
- AWS Lambda: The developer workflow on AWS Lambda involves utilizing services such as AWS SAM or the Serverless Framework for deployment and management. Developers can write functions in various languages like Node.js, Python, Java, and Go. The AWS ecosystem provides extensive tooling for monitoring, logging, and debugging, integrated through services like CloudWatch and X-Ray. A common pattern involves using an API Gateway to trigger Lambda functions based on HTTP requests.
- Azure Functions: Azure Functions offers a workflow tightly integrated with the Azure ecosystem. Developers can write functions in C#, JavaScript, Python, Java, and other languages, using the Azure Functions Core Tools for local development and testing. Deployment is often handled through the Azure portal, Azure CLI, or CI/CD pipelines. The Azure Monitor service provides comprehensive monitoring and logging capabilities. Azure Functions often use Azure Event Grid for event-driven architectures.
- Google Cloud Functions: Google Cloud Functions allows developers to write functions in Node.js, Python, Go, and Java. The Google Cloud Functions Framework supports local development and testing. Deployment is typically done through the Google Cloud Console or the gcloud CLI. Google Cloud Operations (formerly Stackdriver) provides monitoring, logging, and error reporting. Common patterns involve using Cloud Functions to process events from Cloud Storage or Pub/Sub.
Code Development and Deployment

The development and deployment of serverless applications present unique challenges and opportunities compared to traditional infrastructure models. The ephemeral nature of serverless functions, the reliance on cloud provider services, and the distributed architecture necessitate a different approach to coding, testing, and deployment. A robust and well-defined process is crucial for ensuring the reliability, scalability, and maintainability of serverless applications. This section will explore the key aspects of code development and deployment in a serverless context, providing practical guidance and best practices.
Deploying a Simple Serverless Function: A Procedural Guide
Deploying a serverless function typically involves several steps, from writing the code to configuring the necessary infrastructure and finally deploying the function to a cloud provider. This process is often streamlined through the use of serverless frameworks and tooling. Below is a procedural guide for deploying a simple “Hello, World!” function using a hypothetical cloud provider and a command-line interface (CLI).
- Setting up the Development Environment: Before starting, ensure that the necessary tools are installed. This includes the cloud provider’s CLI (e.g., AWS CLI, Azure CLI, Google Cloud SDK), a suitable code editor or IDE, and a runtime environment (e.g., Node.js, Python, Java). The cloud provider’s CLI allows interaction with the provider’s services from the command line, such as deploying functions, managing resources, and viewing logs.
- Writing the Function Code: Create a new directory for the project. Within this directory, create a file for the function’s code (e.g., `index.js` for a Node.js function). The function should accept an event object as input and return a response. For a “Hello, World!” example in Node.js:
“`javascript exports.handler = async (event) => const response = statusCode: 200, body: JSON.stringify(‘Hello, World!’), ; return response; ; “` - Configuring the Deployment: Create a configuration file (e.g., `serverless.yml` or `cloudformation.yml`, depending on the framework used) that defines the function’s name, runtime, handler (the entry point in the code), and any necessary resources, such as API gateways or databases. This configuration file tells the serverless framework or cloud provider how to deploy and manage the function. An example `serverless.yml` file:
“`yaml service: hello-world-function provider: name: aws runtime: nodejs16.x functions: hello: handler: index.handler events:http
path: /hello method: get “`
- Deploying the Function: Using the cloud provider’s CLI or the serverless framework, execute the deployment command. For example, with the Serverless Framework, it might be `serverless deploy`. This command packages the code, uploads it to the cloud provider, creates the necessary infrastructure (if not already present), and configures the function. The CLI will output the endpoint URL for the deployed function.
- Testing the Function: Once deployed, test the function by sending a request to the provided endpoint URL. This can be done using a web browser, `curl`, or a tool like Postman. The expected response should be the “Hello, World!” message.
- Monitoring and Management: After deployment, monitor the function’s performance, logs, and any errors using the cloud provider’s monitoring tools. Configure alerts to be notified of any issues. This is crucial for identifying and resolving problems.
Best Practices for Writing and Structuring Code for Serverless Environments
Writing effective code for serverless environments requires careful consideration of several factors, including function size, resource utilization, and code organization. Following best practices can significantly improve the performance, scalability, and maintainability of serverless applications.
- Keep Functions Small and Focused: Each serverless function should perform a single, well-defined task. This “single responsibility principle” makes the code easier to understand, test, and maintain. Small functions also scale more effectively, as they can be executed concurrently without impacting each other.
- Optimize Code for Cold Starts: Cold starts are the initial latency when a serverless function is invoked after a period of inactivity. Minimizing cold start times is crucial for a good user experience. Techniques include keeping the function code size small, using optimized dependencies, and pre-warming functions (e.g., through scheduled invocations) if supported by the cloud provider.
- Manage Dependencies Efficiently: Carefully manage dependencies to avoid unnecessary code bloat. Use only the required dependencies and consider techniques like dependency bundling or tree-shaking to reduce the size of the deployed package. Regularly update dependencies to benefit from security patches and performance improvements.
- Use Asynchronous Operations: Serverless functions often interact with external services (databases, APIs, etc.). Utilize asynchronous operations (e.g., `async/await` in JavaScript, `asyncio` in Python) to prevent blocking the function’s execution and to improve concurrency.
- Handle Errors Gracefully: Implement robust error handling and logging to diagnose and resolve issues quickly. Catch exceptions, log detailed error messages, and provide informative responses to the client. Utilize a structured logging approach (e.g., JSON logging) for easier analysis.
- Leverage Cloud Provider Services: Utilize cloud provider-managed services whenever possible (e.g., databases, queues, object storage). These services often offer built-in scalability, reliability, and security features, reducing the operational burden and development time.
- Implement Security Best Practices: Secure serverless functions by following security best practices. Use least privilege access control, encrypt sensitive data, validate inputs, and regularly audit dependencies for vulnerabilities.
Strategies for Efficient Code Testing and Debugging in Serverless Applications
Testing and debugging serverless applications present unique challenges due to their distributed nature and reliance on cloud services. Effective strategies are essential for ensuring code quality and quickly resolving issues.
- Unit Testing: Write unit tests for individual functions to verify their behavior in isolation. Mock external dependencies (e.g., database connections, API calls) to control the testing environment and ensure consistent results. Utilize testing frameworks specific to the programming language and environment (e.g., Jest for JavaScript, pytest for Python).
- Integration Testing: Perform integration tests to verify the interaction between different functions and cloud services. Deploy the functions to a testing environment and test the entire workflow. This helps to identify issues related to function interactions, network connectivity, and service configurations.
- End-to-End Testing: Conduct end-to-end tests to validate the complete user experience, from the client-side application to the serverless functions and backend services. These tests simulate real-world scenarios and ensure that the application functions as expected.
- Local Development and Emulation: Utilize local development environments and emulators to test and debug functions without deploying them to the cloud. Cloud providers often offer tools for local function invocation, debugging, and testing, allowing developers to iterate quickly.
- Logging and Monitoring: Implement comprehensive logging to capture detailed information about function execution, including input, output, and any errors. Utilize cloud provider monitoring tools to track function performance, identify bottlenecks, and detect anomalies. Analyze logs to pinpoint the root cause of issues.
- Remote Debugging: Use remote debugging tools to debug functions running in the cloud. Most cloud providers support remote debugging, allowing developers to step through code, inspect variables, and identify issues in real-time.
- Version Control and Continuous Integration/Continuous Deployment (CI/CD): Employ version control systems (e.g., Git) to manage code changes and facilitate collaboration. Integrate CI/CD pipelines to automate the build, test, and deployment processes. This ensures that code changes are thoroughly tested and deployed reliably.
Monitoring and Observability in Serverless
Monitoring and observability are crucial pillars for the successful operation of serverless applications. Due to the ephemeral nature of serverless functions and the distributed architecture they embody, traditional monitoring approaches often fall short. Effective monitoring and observability provide insights into application performance, identify potential issues, and facilitate rapid debugging, ensuring application health and resilience.
Importance of Monitoring and Observability
Serverless applications present unique challenges to monitoring. The short-lived nature of functions, the distributed nature of the architecture, and the reliance on managed services necessitate a proactive and sophisticated approach. Without robust monitoring and observability, developers are blind to critical issues, leading to performance degradation, unexpected costs, and potential outages. Observability, encompassing metrics, logs, and traces, allows developers to understand the internal state of a system.
Monitoring is the process of collecting and analyzing these data points to identify trends and anomalies.
Key Metrics and Logs for Application Health
A comprehensive monitoring strategy for serverless applications must encompass various metrics and logs. Tracking these data points enables developers to understand the application’s behavior, identify bottlenecks, and proactively address potential problems.
- Invocation Metrics: These metrics provide insights into the frequency and duration of function executions.
- Invocation Count: Measures the number of times a function is triggered. High invocation counts can indicate increased traffic or potential issues with event triggers.
- Duration: Tracks the time a function takes to execute. Long durations can signal performance bottlenecks within the function code or dependencies.
- Cold Starts: Measures the time taken for a function to start when no instances are available. High cold start times can negatively impact user experience.
- Errors: Records the number of function executions that result in errors. Monitoring error rates is crucial for identifying and resolving bugs.
- Resource Utilization Metrics: Monitoring resource utilization helps identify resource constraints and optimize function configurations.
- Memory Usage: Tracks the amount of memory a function consumes during execution. Excessive memory usage can lead to performance degradation or function failures.
- CPU Utilization: Measures the CPU resources consumed by a function. High CPU utilization can indicate computationally intensive tasks or inefficient code.
- Concurrent Executions: Tracks the number of function instances running concurrently. Monitoring concurrency helps prevent resource exhaustion and ensures scalability.
- Dependency Metrics: Monitoring interactions with external services is essential for identifying issues with dependencies.
- API Response Times: Measures the time taken for API calls to external services. Slow response times can impact application performance.
- API Error Rates: Tracks the number of errors returned by external services. High error rates can indicate issues with the services themselves or with the application’s integration.
- Database Connection Metrics: Track database connection pool usage, query latency, and error rates.
- Log Data: Logs provide detailed information about function executions, including error messages, debug information, and application-specific events.
- Function Logs: Contain information about function executions, including start and end times, input and output data, and any errors that occurred.
- Access Logs: Record information about incoming requests, including the request method, URL, and client IP address.
- Custom Logs: Developers can add custom logs to track application-specific events and data.
Integrating Monitoring Tools with Serverless Platforms
Integrating monitoring tools with serverless platforms is essential for collecting and analyzing the metrics and logs necessary for effective monitoring and observability. Most serverless platforms offer native integrations with popular monitoring and observability solutions, streamlining the setup process.
- CloudWatch (AWS): Amazon CloudWatch provides comprehensive monitoring and observability capabilities for AWS services, including serverless functions. Developers can configure CloudWatch to collect metrics and logs from their functions, set up alarms to detect anomalies, and create dashboards to visualize application performance.
- Cloud Functions (Google Cloud): Google Cloud Functions integrates with Google Cloud Monitoring (formerly Stackdriver) and Cloud Logging. This integration enables developers to monitor function metrics, view logs, and create custom dashboards.
- Azure Monitor (Azure): Azure Monitor provides monitoring and observability capabilities for Azure services, including Azure Functions. Developers can use Azure Monitor to collect metrics and logs, set up alerts, and analyze application performance.
- Third-Party Tools: Several third-party monitoring and observability tools, such as Datadog, New Relic, and Dynatrace, offer integrations with serverless platforms. These tools provide advanced features, such as distributed tracing and anomaly detection. For example, Datadog offers specific dashboards and monitors tailored for serverless architectures, allowing for deep insights into function performance, latency, and error rates.
- Implementation Examples:
- AWS Lambda and CloudWatch: When a Lambda function is created, CloudWatch automatically starts collecting metrics like invocations, errors, and duration. Developers can then create custom metrics by emitting log data that CloudWatch can parse. For instance, logging the execution time of specific code blocks within a function allows for granular performance analysis. Setting up alarms based on these metrics allows for proactive responses to issues, such as scaling the function if latency exceeds a certain threshold.
- Google Cloud Functions and Cloud Monitoring/Logging: Google Cloud Functions automatically sends logs and metrics to Cloud Logging and Cloud Monitoring, respectively. Developers can create custom metrics and logs within their function code. They can then create dashboards to visualize these metrics, and set up alerting rules based on thresholds. For example, monitoring the rate of requests to a specific API endpoint can help identify potential denial-of-service attacks or performance bottlenecks.
- Azure Functions and Azure Monitor: Azure Functions integrates with Azure Monitor, providing automatic collection of metrics and logs. Developers can extend this by using Application Insights, a feature of Azure Monitor, to gain detailed insights into the performance and health of their functions. This includes features like distributed tracing, which allows developers to track requests across multiple function calls and services.
Local Development and Emulation
The ability to develop and test serverless applications locally is a crucial aspect of the developer experience (DevEx). Local development environments offer significant advantages in terms of speed, cost, and convenience, allowing developers to iterate rapidly and catch errors early in the development lifecycle. This section explores the landscape of local development and emulation for serverless applications, examining various approaches, workflows, and their respective benefits and limitations.
Comparing Local Development Environments for Serverless Applications
Different approaches exist for enabling local development of serverless applications, each with its own set of trade-offs. These environments aim to mimic the behavior of cloud-based serverless platforms, such as AWS Lambda, Google Cloud Functions, and Azure Functions, allowing developers to test their code without deploying it to the cloud.
- Container-based Emulation: Containerization, using technologies like Docker, is a popular method for creating local development environments. This approach involves creating Docker containers that replicate the runtime environments of the target serverless platform. For instance, a Docker container can be configured to run the Node.js runtime environment used by AWS Lambda, allowing developers to execute their JavaScript functions locally.
The benefits include consistency between the local and cloud environments, as the containerized environment closely mirrors the production environment. Limitations include the potential overhead of container startup and resource consumption, especially for complex applications with numerous dependencies.
- Lightweight Simulators: Lightweight simulators, such as `Serverless Offline` or `LocalStack`, provide simplified emulations of serverless services. These tools often focus on emulating specific services, such as API Gateway, S3, or DynamoDB, without requiring full containerization. This approach offers faster startup times and lower resource consumption compared to container-based methods. However, they may not perfectly replicate the behavior of the cloud platform, potentially leading to subtle differences in behavior that are only discovered during cloud deployment.
- Platform-Specific SDKs and CLIs: Cloud providers often offer SDKs and CLIs that facilitate local testing and debugging. For example, the AWS SAM CLI (Serverless Application Model Command Line Interface) allows developers to test Lambda functions locally using a local runtime environment. These tools often provide a more integrated development experience, with features such as local invocation, debugging, and event simulation. However, they are typically tied to a specific cloud provider and may not be suitable for multi-cloud or hybrid cloud environments.
Designing a Local Workflow for Testing and Debugging Serverless Functions
A well-designed local workflow is essential for efficient serverless development. The workflow should enable developers to quickly test, debug, and iterate on their code without repeatedly deploying to the cloud.
- Local Development Environment Setup: Choose an appropriate local development environment based on the project’s requirements and the chosen cloud provider. This might involve setting up Docker containers, installing a lightweight simulator, or configuring the cloud provider’s CLI tools.
- Function Development and Testing: Write and test serverless functions locally. Use the chosen environment to invoke functions, simulate events, and verify the expected behavior. Implement unit tests and integration tests to ensure code quality and functionality.
- Debugging: Utilize debugging tools to identify and resolve issues. Many IDEs (Integrated Development Environments) offer debugging support for serverless functions, allowing developers to set breakpoints, inspect variables, and step through code execution. Local emulators and CLIs often provide debugging capabilities, such as logging and error reporting.
- Integration with CI/CD Pipelines: Integrate local testing into the continuous integration/continuous deployment (CI/CD) pipeline. This ensures that code changes are automatically tested before being deployed to the cloud. Use tools like `Jest` or `Mocha` for automated testing and integrate them with the CI/CD pipeline.
Benefits and Limitations of Local Emulators for Serverless Development
Local emulators provide a valuable toolset for serverless development, but it is important to understand their limitations.
- Benefits:
- Faster Development Cycles: Local emulators significantly reduce the time required to test and debug serverless functions, as developers can iterate quickly without deploying to the cloud.
- Reduced Cloud Costs: Local testing eliminates the need to incur cloud costs for testing and debugging, especially for applications that involve frequent deployments.
- Improved Developer Productivity: Local emulators provide a more responsive and efficient development experience, leading to increased developer productivity.
- Offline Development: Local emulators allow developers to work on serverless applications even without an internet connection.
- Limitations:
- Incomplete Emulation: Local emulators may not perfectly replicate the behavior of the cloud platform, potentially leading to subtle differences in behavior that are only discovered during cloud deployment.
- Performance Differences: The performance characteristics of local emulators may differ from those of the cloud platform, potentially leading to inaccurate performance testing.
- Complexity: Setting up and configuring local emulators can be complex, especially for applications that use multiple serverless services.
- Dependency on Third-Party Tools: Local emulators often rely on third-party tools, which may introduce additional dependencies and potential compatibility issues.
Security Considerations for Serverless DevEx
The serverless developer experience (DevEx) significantly impacts the security posture of applications. While serverless platforms often handle much of the underlying infrastructure security, developers retain significant responsibility for securing their code, configurations, and access controls. A robust DevEx must prioritize security throughout the development lifecycle, from code writing to deployment and monitoring. Neglecting security in this context can expose applications to a range of vulnerabilities, potentially leading to data breaches, service disruptions, and reputational damage.
Security Best Practices for Serverless Applications and Developer Responsibilities
Developers are the first line of defense in serverless security. They must adopt a proactive approach, integrating security considerations into every stage of the development process. This includes secure coding practices, rigorous testing, and diligent configuration management.
- Secure Coding Practices: Developers should adhere to established secure coding standards, such as those Artikeld by OWASP (Open Web Application Security Project). This involves:
- Input validation and sanitization to prevent injection attacks (e.g., SQL injection, cross-site scripting).
- Proper handling of sensitive data, including encryption both in transit and at rest. For instance, encrypting data stored in serverless databases like DynamoDB or using KMS (Key Management Service) for encryption keys.
- Avoiding hardcoding secrets (API keys, passwords) in the code. Instead, leverage environment variables or secret management services.
- Implementing robust error handling and logging to identify and address potential vulnerabilities.
- Least Privilege Principle: Grant functions only the necessary permissions to access resources. This minimizes the impact of a potential compromise. For example, a function that processes images should not have full access to a database. Utilize IAM (Identity and Access Management) roles to define and enforce these permissions.
- Regular Dependency Updates: Serverless applications often rely on third-party libraries and dependencies. Regularly update these dependencies to patch known vulnerabilities. Use tools like Snyk or Dependabot to automate vulnerability scanning and updates.
- Infrastructure as Code (IaC): Utilize IaC tools (e.g., AWS CloudFormation, Terraform) to define and manage infrastructure in a consistent and secure manner. This allows for version control, automated security checks, and reduces the risk of manual configuration errors.
- Security Testing: Implement comprehensive security testing throughout the development lifecycle. This includes:
- Static code analysis to identify potential vulnerabilities in the code.
- Dynamic application security testing (DAST) to simulate attacks and identify runtime vulnerabilities.
- Penetration testing to assess the overall security posture of the application.
- Monitoring and Logging: Implement robust monitoring and logging to detect and respond to security incidents. This includes:
- Centralized logging to collect and analyze logs from all serverless functions and related services.
- Real-time monitoring to detect suspicious activity, such as unusual access patterns or elevated error rates.
- Alerting mechanisms to notify developers of potential security threats.
- Secrets Management: Securely store and manage sensitive information like API keys, database credentials, and other secrets. Leverage services like AWS Secrets Manager or HashiCorp Vault.
Common Security Vulnerabilities in Serverless Environments
Serverless environments introduce unique security challenges. Developers must be aware of common vulnerabilities to proactively mitigate risks.
- Injection Attacks: Serverless functions, like any web application, are susceptible to injection attacks if input validation is not properly implemented. SQL injection, command injection, and cross-site scripting (XSS) are common examples.
- Broken Authentication and Authorization: Improperly configured authentication and authorization mechanisms can allow unauthorized access to resources. This includes issues like weak passwords, missing multi-factor authentication (MFA), and overly permissive IAM roles.
- Sensitive Data Exposure: Failure to encrypt sensitive data in transit and at rest can lead to data breaches. This includes data stored in databases, object storage (e.g., S3 buckets), and logs.
- XML External Entities (XXE): If serverless functions process XML data, they may be vulnerable to XXE attacks, allowing attackers to access sensitive data or execute arbitrary code.
- Insecure Deserialization: If a serverless function deserializes untrusted data, attackers may be able to execute malicious code.
- Denial of Service (DoS) and Distributed Denial of Service (DDoS): Serverless applications can be targeted by DoS and DDoS attacks, overwhelming the resources and making the application unavailable. This can be mitigated through rate limiting, web application firewalls (WAFs), and other security measures.
- Function Code Vulnerabilities: Vulnerabilities within the function code itself, such as buffer overflows or logic errors, can be exploited by attackers.
- Misconfigured Serverless Services: Improper configuration of serverless services (e.g., overly permissive S3 bucket policies, misconfigured API Gateway settings) can create security vulnerabilities.
- Supply Chain Attacks: Compromised dependencies or third-party libraries can introduce vulnerabilities into the serverless application.
Implementing Secure Access Controls for Serverless Resources: A Scenario
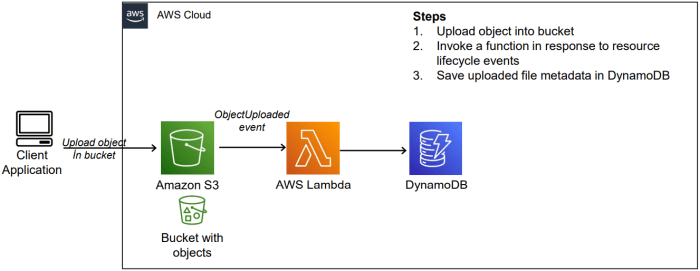
Consider a scenario where a company, “CloudCorp,” is developing a serverless image processing application using AWS Lambda, API Gateway, S3, and DynamoDB. The application allows users to upload images, which are then processed and stored. Secure access control is crucial to protect the images and prevent unauthorized access or modification.
- IAM Roles and Permissions:
- Create distinct IAM roles for each Lambda function. For example, an “ImageUploadFunctionRole” and an “ImageProcessingFunctionRole.”
- The “ImageUploadFunctionRole” is granted permissions to:
- Write objects to a designated S3 bucket (“cloudcorp-image-uploads”).
- Access the KMS key used to encrypt the uploaded images.
- The “ImageProcessingFunctionRole” is granted permissions to:
- Read objects from the “cloudcorp-image-uploads” S3 bucket.
- Write objects to a different S3 bucket (“cloudcorp-image-processed”).
- Read and write to a DynamoDB table (“cloudcorp-image-metadata”) to store image metadata.
- Access the KMS key used to encrypt the processed images and the DynamoDB table.
- Neither role should have broad permissions, such as full S3 access or full DynamoDB access.
- API Gateway Authentication and Authorization:
- Configure API Gateway to use an authentication mechanism, such as API keys or a custom authorizer.
- If using API keys, ensure that the keys are properly protected and that the API Gateway usage plans limit the number of requests per key.
- If using a custom authorizer, the authorizer function should validate user credentials and determine the user’s permissions. For example, only authenticated users should be able to upload images.
- S3 Bucket Policies:
- Configure S3 bucket policies to restrict access to the uploaded and processed images.
- The “cloudcorp-image-uploads” bucket policy should allow only the “ImageUploadFunctionRole” to write objects.
- The “cloudcorp-image-processed” bucket policy should allow only authorized users (authenticated through API Gateway) to read objects.
- Data Encryption:
- Encrypt all images stored in S3 using KMS.
- Encrypt the DynamoDB table (“cloudcorp-image-metadata”) using KMS.
- Ensure that sensitive data, such as user information, is encrypted both in transit (using HTTPS) and at rest (in databases and object storage).
- Logging and Monitoring:
- Enable detailed logging for all Lambda functions, API Gateway, and S3.
- Monitor the logs for any suspicious activity, such as unauthorized access attempts or unusual error rates.
- Set up alerts to notify the development team of potential security incidents. For instance, create an alert if a function fails repeatedly or if a large number of unauthorized access attempts are logged.
This scenario illustrates how to implement a layered approach to secure access control, focusing on the principle of least privilege and utilizing a combination of IAM roles, API Gateway authentication, S3 bucket policies, data encryption, and monitoring. This approach reduces the attack surface and protects the application and its data from unauthorized access. For example, if a Lambda function is compromised, the limited permissions assigned to its IAM role restrict the damage an attacker can inflict.
Similarly, if an API key is leaked, the rate limiting imposed by the API Gateway usage plan can mitigate the impact of the compromise.
Collaboration and Teamwork in Serverless

Serverless architectures, by their nature, promote a shift in how teams collaborate and approach the development lifecycle. The distributed nature of serverless applications necessitates a streamlined approach to team dynamics, version control, and deployment processes. Effective collaboration becomes paramount to ensure that independently developed functions integrate seamlessly and that the overall application functions as intended. This section examines the impact of serverless on team collaboration and development, providing practical strategies for successful team-based serverless projects.
Impact of Serverless Architectures on Team Collaboration
Serverless architectures inherently influence team dynamics by promoting a microservices-like approach. Teams often break down into smaller units, each responsible for specific serverless functions or sets of functions. This decomposition offers several advantages, including increased agility, faster development cycles, and improved fault isolation. However, this distributed nature also introduces new challenges that must be addressed to maintain effective collaboration.
- Decentralized Ownership: Serverless encourages decentralized ownership of code. Each function or set of functions can be owned by a specific team or individual, leading to greater autonomy and faster iteration. However, this also requires clear communication and coordination to prevent conflicts and ensure consistent application behavior.
- Increased Focus on APIs: Serverless applications rely heavily on APIs for communication between functions. This emphasis on APIs necessitates a strong focus on API design, documentation, and versioning. Teams must collaborate on API contracts to ensure compatibility and interoperability between different functions.
- Simplified Deployment Pipelines: Serverless platforms often offer built-in tools and services for managing deployments. These tools can simplify the deployment process, enabling teams to deploy updates quickly and independently. However, teams must still manage the complexities of coordinating deployments across multiple functions and services.
- Enhanced Need for Observability: With distributed applications, monitoring and observability become critical. Teams must implement robust monitoring and logging systems to track the performance of individual functions and the overall application. This requires collaboration between development, operations, and security teams.
- Shared Responsibility for Security: In serverless, security is a shared responsibility. While the serverless platform handles some security aspects, teams are responsible for securing their functions and data. This necessitates collaboration between development and security teams to implement appropriate security measures.
Methods for Managing Code Versioning and Deployment Pipelines in a Team Environment
Effective versioning and deployment strategies are critical for managing serverless projects in a team environment. These strategies ensure that code changes are tracked, deployed reliably, and rolled back if necessary. Adopting these practices minimizes disruptions and fosters a collaborative development workflow.
- Version Control Systems (VCS): Utilizing a VCS, such as Git, is fundamental for managing code versions. Each team member should work on their feature branch, creating pull requests for code review and integration.
- Branching Strategies: Employing branching strategies like Gitflow or GitHub Flow helps manage code changes and releases. For example, Gitflow uses branches for features, releases, and hotfixes, enabling organized development and release processes.
- Automated Testing: Implementing automated unit, integration, and end-to-end tests is essential. Tests should be executed as part of the CI/CD pipeline to validate code changes before deployment.
- Infrastructure as Code (IaC): IaC tools, such as AWS CloudFormation, Terraform, or Serverless Framework, allow infrastructure to be defined as code. This promotes consistency, reproducibility, and versioning of infrastructure configurations.
- Deployment Pipelines: Implementing CI/CD pipelines automates the build, test, and deployment processes. These pipelines typically include steps for building code, running tests, deploying to staging environments, and promoting code to production.
- Rollback Strategies: Having rollback strategies in place is crucial. These can include deploying previous versions of functions, reverting infrastructure changes, or using feature flags to disable problematic features.
- Secrets Management: Securely managing secrets, such as API keys and database credentials, is vital. Utilize tools like AWS Secrets Manager or HashiCorp Vault to store and manage secrets.
Design a Workflow for Continuous Integration and Continuous Deployment (CI/CD) in Serverless Projects
A well-defined CI/CD workflow is critical for accelerating development cycles and ensuring the reliable delivery of serverless applications. This workflow automates the build, test, and deployment processes, minimizing manual intervention and reducing the risk of errors. A typical CI/CD pipeline for serverless projects includes several key stages.
- Code Commit: Developers commit code changes to a version control repository (e.g., Git).
- Trigger: The CI/CD pipeline is triggered automatically by a code commit, a scheduled event, or a manual trigger.
- Build Stage:
- Install dependencies (e.g., using npm, pip, or similar package managers).
- Perform static code analysis and linting.
- Package the code into deployable artifacts (e.g., a ZIP file for AWS Lambda functions).
- Test Stage:
- Run unit tests to verify individual function logic.
- Execute integration tests to validate interactions between functions and other services.
- Conduct end-to-end tests to simulate user scenarios and validate the application’s functionality.
- Deployment Stage:
- Deploy the serverless functions and related infrastructure to a staging environment.
- Run additional tests in the staging environment.
- If tests pass, promote the code to the production environment.
- Consider blue/green deployments or canary releases to minimize downtime and risk.
- Monitoring and Alerting:
- Monitor the performance and health of the deployed functions using monitoring tools (e.g., AWS CloudWatch, Datadog, or New Relic).
- Set up alerts to notify the team of any issues or anomalies.
An example of a CI/CD pipeline for a serverless application could use GitHub Actions, GitLab CI, or AWS CodePipeline. These tools can be configured to automatically build, test, and deploy serverless functions upon code commits. For instance, a pipeline might include steps to build a Node.js function, run unit tests, deploy the function to a staging environment using the Serverless Framework, run integration tests, and then deploy to production if all tests pass.
Cost Optimization in Serverless
Serverless architectures, while offering significant advantages in scalability and developer productivity, introduce a unique set of cost considerations. The pay-per-use model, the core principle of serverless, can lead to both substantial cost savings and unexpected expenses if not managed effectively. Understanding how various serverless components contribute to the overall cost and implementing proactive optimization strategies are crucial for maximizing the return on investment (ROI) in serverless applications.
This section details the factors influencing serverless costs and provides actionable strategies for cost control.Serverless architectures significantly impact application costs through their inherent pay-per-use pricing model. This model charges users only for the actual resources consumed, such as compute time, memory usage, and the number of requests. This contrasts with traditional infrastructure where users pay for provisioned resources regardless of utilization.
This can lead to significant cost reductions, particularly for applications with variable workloads or periods of low traffic. However, it also necessitates careful monitoring and optimization to prevent runaway costs, especially in the event of unexpected traffic spikes or inefficient code. The granularity of serverless pricing allows for precise cost allocation, but also demands meticulous attention to detail to identify and eliminate inefficiencies.
For example, a poorly optimized function that consumes excessive memory or runs for an extended duration will incur higher costs compared to a function designed for optimal resource utilization. The dynamic nature of serverless environments also requires a proactive approach to cost management, including the use of automated tools and alerts to detect and address potential cost issues promptly.
Cost Optimization Strategies for Serverless Components
Effective cost optimization in serverless requires a component-specific approach. Each serverless service, from compute functions to databases, has its own pricing model and potential areas for optimization. The following table provides a detailed overview of cost optimization strategies, categorized by component type, along with concrete examples.
| Component | Optimization Strategy | Example |
|---|---|---|
| Compute Functions (e.g., AWS Lambda, Azure Functions, Google Cloud Functions) | Optimize function code for efficiency. |
|
| API Gateways (e.g., AWS API Gateway, Azure API Management, Google Cloud API Gateway) | Manage API requests effectively. |
|
| Databases (e.g., AWS DynamoDB, Azure Cosmos DB, Google Cloud Firestore) | Optimize database access patterns and resource provisioning. |
|
| Storage (e.g., AWS S3, Azure Blob Storage, Google Cloud Storage) | Manage storage effectively. |
|
| Event Triggers (e.g., AWS EventBridge, Azure Event Grid, Google Cloud Pub/Sub) | Optimize event routing and processing. |
|
Monitoring and Controlling Costs in Serverless Applications
Effective cost management in serverless environments hinges on continuous monitoring and proactive control measures. This involves utilizing cloud provider-specific tools, implementing cost alerts, and regularly reviewing cost reports to identify and address potential issues. A multi-faceted approach combining technical solutions with organizational best practices is crucial.To monitor and control costs effectively, consider these key aspects:
- Utilize Cloud Provider Cost Management Tools: Cloud providers offer comprehensive cost management tools. For example, AWS Cost Explorer provides detailed cost breakdowns, forecasting capabilities, and anomaly detection. Azure Cost Management + Billing offers similar features. Google Cloud’s Cloud Billing provides cost analysis and budgeting tools. These tools allow you to track spending trends, identify cost drivers, and set budgets.
- Implement Cost Alerts and Budgets: Set up cost alerts to be notified when spending exceeds a predefined threshold. Define budgets to limit spending on specific services or projects. Most cloud providers allow you to configure alerts based on various criteria, such as spending amount, projected spending, or resource usage. For instance, set a budget for AWS Lambda invocations and receive an alert if the cost exceeds a certain amount within a month.
- Regularly Review Cost Reports: Regularly analyze cost reports to identify areas where costs can be optimized. This involves examining service-specific costs, identifying trends, and understanding the factors driving cost changes. For example, review AWS Lambda function logs to identify inefficient functions.
- Implement Automated Cost Optimization Strategies: Automate cost optimization tasks where possible. For example, use serverless functions to automatically resize resources based on demand or to move data to lower-cost storage tiers. Employ tools that automatically identify and suggest cost-saving measures.
- Establish Cost-Aware Development Practices: Encourage developers to consider cost implications during the development process. This includes providing training on cost optimization best practices and integrating cost monitoring into the development workflow. Provide guidelines on choosing the right instance sizes, optimizing database queries, and using efficient coding practices.
- Leverage Cost Management Dashboards: Create custom dashboards to visualize cost data and provide a real-time overview of spending. This allows for quick identification of cost anomalies and trends. Integrate data from various sources, such as cloud provider cost reports, application performance metrics, and infrastructure logs.
- Perform Regular Cost Audits: Conduct periodic cost audits to ensure that all cost optimization strategies are being followed and that no unexpected costs are arising. Review the configuration of all serverless resources and identify any areas where costs can be reduced. This can involve a review of function configurations, database settings, and storage tiering policies.
Serverless Frameworks and Abstractions
Serverless frameworks provide a layer of abstraction over the underlying cloud infrastructure, simplifying the development, deployment, and management of serverless applications. These frameworks automate many of the complex tasks associated with serverless, allowing developers to focus on writing business logic rather than configuring infrastructure. They offer a variety of features, including infrastructure-as-code, automated deployments, and simplified event handling. The choice of framework significantly impacts the development workflow, operational overhead, and overall efficiency of serverless projects.
Comparing Popular Serverless Frameworks and Their Features
The serverless landscape features several prominent frameworks, each with its strengths and weaknesses. The selection of a framework depends heavily on the specific project requirements, cloud provider preference, and team expertise. A comparative analysis of key features reveals the nuances of each option.
- AWS Serverless Application Model (SAM): Developed by AWS, SAM is specifically designed for deploying serverless applications on AWS. It extends AWS CloudFormation and uses a simplified YAML syntax to define serverless resources, including functions, APIs, and databases. It provides a local testing environment, supports CI/CD pipelines, and integrates seamlessly with other AWS services. A key advantage is its tight integration with the AWS ecosystem, offering optimized performance and cost management.
However, its vendor lock-in can be a disadvantage.
- Serverless Framework: This is a vendor-agnostic framework that supports multiple cloud providers, including AWS, Azure, and Google Cloud Platform. It uses a YAML configuration file to define infrastructure and application code. The Serverless Framework provides a rich plugin ecosystem for extending functionality, supporting features like custom domain configuration, monitoring, and deployment hooks. It facilitates multi-cloud deployments and offers a broader community support compared to provider-specific frameworks.
However, the abstraction can sometimes lead to slower performance compared to native provider solutions.
- Azure Functions Core Tools: This set of command-line tools is specifically designed for developing, testing, and deploying Azure Functions. It supports various languages, including C#, JavaScript, Python, and Java. The Core Tools provides a local development environment for simulating Azure Functions triggers and bindings. The tight integration with the Azure ecosystem makes it a suitable choice for Azure-centric projects. However, it is less versatile than the Serverless Framework in terms of cloud provider support.
- Google Cloud Functions Framework: Similar to the Core Tools, this framework is designed for building and deploying functions on Google Cloud Platform. It supports multiple languages and provides tools for local development and testing. It integrates closely with other Google Cloud services and offers streamlined deployments. The focus on the Google Cloud ecosystem makes it a strong contender for GCP-based serverless projects.
Simplifying Serverless Development Workflows with Frameworks
Serverless frameworks streamline various aspects of the development lifecycle, from initial setup to ongoing maintenance. They automate tasks that would otherwise require manual configuration and scripting, improving developer productivity and reducing the potential for errors.
- Infrastructure-as-Code (IaC): Frameworks allow developers to define infrastructure in code, typically using YAML or JSON configuration files. This approach enables version control, repeatability, and automated provisioning of serverless resources. The configuration files act as a single source of truth for the application’s infrastructure.
- Automated Deployment: Frameworks automate the deployment process, including packaging code, uploading it to the cloud provider, and configuring triggers and other settings. This eliminates the need for manual steps and reduces the risk of deployment errors. They often integrate with CI/CD pipelines for continuous integration and continuous deployment.
- Simplified Event Handling: Frameworks often provide abstractions for handling events from various sources, such as API Gateway, S3 buckets, and databases. This simplifies the process of connecting serverless functions to event sources and processing event data.
- Local Development and Testing: Many frameworks offer local development environments that allow developers to test and debug serverless functions locally before deploying them to the cloud. This significantly speeds up the development process and reduces the cost of cloud-based testing.
- Monitoring and Logging Integration: Frameworks often integrate with cloud provider’s monitoring and logging services, making it easier to monitor the performance and health of serverless applications. This provides valuable insights into application behavior and helps identify and resolve issues.
Demonstrating Framework Use: Building a Simple Application with the Serverless Framework
This section illustrates the use of the Serverless Framework to build a basic “Hello World” API endpoint on AWS. This example showcases the framework’s ease of use and demonstrates how to define a serverless function, API Gateway endpoint, and deployment configuration.
- Project Setup: Create a new project directory and initialize the Serverless Framework.
serverless create --template aws-nodejs --path my-serverless-appThis command creates a project with a pre-configured `serverless.yml` file and a sample function.
- Defining the Function: Modify the `handler.js` file to include the function’s logic. The following example defines a function that returns a “Hello World” message.
module.exports.hello = async (event) => return statusCode: 200, body: JSON.stringify( message: 'Hello World!', ), ; ; - Configuring the API Gateway: The `serverless.yml` file is used to configure the API Gateway endpoint.
service: my-serverless-app provider: name: aws runtime: nodejs18.x functions: hello: handler: handler.hello events:http
method: get path: /hello
This configuration defines a GET endpoint at `/hello` that triggers the `hello` function.
- Deploying the Application: Deploy the application to AWS using the Serverless Framework.
serverless deployThis command packages the code, creates the necessary AWS resources, and deploys the application. The framework will output the API Gateway endpoint URL.
- Testing the Application: After deployment, access the API endpoint URL in a web browser or using a tool like `curl`. The “Hello World” message should be displayed.
Documentation and Learning Resources
Effective documentation and readily available learning resources are critical components of a positive serverless developer experience (DevEx). They empower developers to understand, implement, and maintain serverless applications efficiently. Comprehensive documentation reduces the learning curve, facilitates collaboration, and minimizes the time spent troubleshooting, while accessible learning materials promote skill development and accelerate project timelines.
Creating Effective Documentation for Serverless Projects
Documentation should be treated as a first-class citizen in any serverless project. Well-structured documentation minimizes ambiguity, enhances maintainability, and improves developer onboarding. The following aspects contribute to effective serverless project documentation.
- Project Overview and Architecture: A high-level description of the project’s purpose, goals, and architectural design is essential. This should include diagrams illustrating the system’s components, their interactions, and the data flow.
- Function Definitions and API Specifications: Each serverless function should have a clear definition, including its purpose, input parameters, output formats, and any error handling strategies. API specifications, such as OpenAPI (Swagger) definitions, are vital for describing endpoints, request/response structures, and authentication mechanisms.
- Deployment and Configuration: Detailed instructions on how to deploy the serverless application, including the necessary configuration parameters (environment variables, IAM roles, etc.) and any infrastructure-as-code (IaC) templates used (e.g., CloudFormation, Terraform, or Serverless Framework configuration).
- Monitoring and Logging: Explain how to monitor the application’s performance and health. This should cover metrics tracked, logging practices, and the tools used (e.g., CloudWatch, Datadog, or custom dashboards). Include examples of log formats and error codes.
- Security Considerations: Document the security best practices implemented in the project. This includes information about authentication, authorization, data encryption, and vulnerability management.
- Code Examples and Tutorials: Provide concise, practical code examples demonstrating how to use different serverless components and interact with external services. Step-by-step tutorials guide developers through common use cases.
- Versioning and Updates: Implement versioning for the documentation to track changes and maintain compatibility with different versions of the application. Clearly communicate the updates and their impact on the developers.
- Contribution Guidelines: Artikel the process for contributing to the documentation, including style guides, formatting conventions, and review processes.
Valuable Learning Resources for Serverless Development
The serverless ecosystem offers a wealth of learning resources. These resources vary in format and focus, catering to different learning styles and experience levels. Leveraging these resources allows developers to quickly gain the necessary knowledge and skills.
- Official Cloud Provider Documentation: The official documentation from cloud providers (AWS, Azure, Google Cloud) is the primary source of information about their serverless services. These resources provide in-depth details, tutorials, and API references.
- Serverless Framework Documentation: Frameworks like the Serverless Framework, AWS SAM, and Azure Functions Core Tools provide detailed documentation on how to build, deploy, and manage serverless applications.
- Online Courses and Tutorials: Platforms like Udemy, Coursera, and A Cloud Guru offer a wide variety of courses and tutorials on serverless technologies. These courses range from introductory overviews to advanced topics.
- Blogs and Articles: Numerous blogs and articles provide practical insights, best practices, and case studies on serverless development. Well-known blogs and websites are maintained by cloud providers, technology companies, and independent developers.
- Open-Source Projects and Code Repositories: Exploring open-source projects and code repositories provides valuable insights into real-world serverless applications. Developers can learn from the code, architecture, and implementation details of these projects.
- Community Forums and Online Communities: Platforms like Stack Overflow, Reddit (e.g., r/serverless), and dedicated community forums allow developers to ask questions, share knowledge, and learn from each other.
- Conferences and Meetups: Attending serverless conferences and meetups offers opportunities to learn from experts, network with other developers, and stay up-to-date on the latest trends.
Structure for Organizing a Comprehensive Knowledge Base for Serverless Developers
A well-organized knowledge base is essential for centralizing information and facilitating knowledge sharing within a team or organization. The following structure helps organize information effectively.
- Introduction and Overview: A brief overview of the serverless technologies used, project goals, and key concepts.
- Getting Started Guides: Step-by-step instructions for setting up the development environment, deploying a basic application, and configuring common tools.
- Tutorials and Code Examples: Practical examples and tutorials demonstrating how to implement specific functionalities, integrate with external services, and address common use cases.
- API Reference and Documentation: Comprehensive documentation for all APIs, functions, and services used in the project, including input/output parameters, error codes, and usage examples.
- Troubleshooting and FAQs: A collection of common issues, error messages, and their solutions.
- Best Practices and Guidelines: Recommendations for security, performance, cost optimization, and other critical aspects of serverless development.
- Glossary of Terms: Definitions of key serverless concepts and terminology.
- Links to External Resources: Links to relevant documentation, articles, tutorials, and community resources.
- Version Control and Updates: A system for tracking changes to the knowledge base and ensuring that the information remains up-to-date.
Future Trends and Innovations in Serverless DevEx
The serverless developer experience (DevEx) is a rapidly evolving landscape, driven by continuous innovation and the need for greater efficiency, scalability, and ease of use. As serverless adoption continues to grow, several emerging trends and potential innovations are poised to reshape how developers build, deploy, and manage serverless applications. These advancements promise to address current limitations and unlock new possibilities for serverless development.
Advanced Automation and Orchestration
Automation will play an increasingly crucial role in streamlining serverless workflows. The goal is to minimize manual intervention and optimize the entire development lifecycle.
- Intelligent CI/CD Pipelines: Automated Continuous Integration and Continuous Delivery (CI/CD) pipelines will become more sophisticated, leveraging machine learning to optimize build times, identify performance bottlenecks, and automatically roll back deployments in case of errors. For example, tools might analyze code changes and predict the impact on performance, triggering specific tests or adjusting resource allocation accordingly. This proactive approach can prevent outages and improve application stability.
- Automated Infrastructure Provisioning: Infrastructure-as-Code (IaC) tools will become even more tightly integrated with serverless platforms. This integration will allow developers to define and manage their serverless infrastructure (functions, APIs, databases, etc.) using code, ensuring consistency and reproducibility. Tools will also automate the deployment and configuration of these resources, reducing the time and effort required to set up a serverless application.
Consider the use of tools like Terraform or AWS CloudFormation, but with enhanced features for serverless specific deployments, allowing for automated scaling and resource optimization based on real-time application needs.
- Self-Healing and Self-Optimizing Systems: Serverless applications will increasingly incorporate self-healing and self-optimizing capabilities. This will involve monitoring application performance and automatically adjusting resource allocation (e.g., scaling functions, adjusting memory settings) to maintain optimal performance and availability. This could be achieved by using tools that leverage AI and machine learning to analyze application metrics and identify areas for improvement.
Enhanced Developer Tooling and Frameworks
Developer tooling and frameworks will evolve to provide a more seamless and productive development experience. This will involve improved debugging, testing, and collaboration features.
- Integrated Development Environments (IDEs) with Serverless Support: IDEs will provide more comprehensive support for serverless development, including built-in debugging, testing, and deployment capabilities. They will offer intelligent code completion, syntax highlighting, and real-time feedback to help developers write and debug serverless functions more efficiently. This could also include features like local function execution and debugging.
- Serverless-Specific Testing Frameworks: Dedicated testing frameworks will emerge to address the unique challenges of testing serverless applications. These frameworks will enable developers to easily test their functions in isolation, simulate various event triggers, and mock external services. This will lead to more reliable and robust serverless applications. Consider frameworks that facilitate testing event-driven architectures, allowing developers to simulate different event sources (e.g., API Gateway, S3 buckets, etc.) and test how their functions respond.
- Low-Code/No-Code Serverless Platforms: The rise of low-code/no-code platforms will extend the reach of serverless development to a broader audience. These platforms will allow developers to build serverless applications with minimal coding, using visual interfaces and pre-built components. This will accelerate development and reduce the barrier to entry for serverless technology. Examples include platforms that offer drag-and-drop interfaces for creating APIs and integrating with various services.
Advanced Monitoring and Observability
Comprehensive monitoring and observability capabilities are critical for managing and optimizing serverless applications. These capabilities will become more sophisticated and integrated.
- Real-Time Performance Monitoring: Real-time performance monitoring dashboards will provide developers with a comprehensive view of their application’s performance, including metrics such as function execution time, error rates, and resource utilization. These dashboards will use real-time data streams to provide instant feedback on application behavior. This will include advanced features like distributed tracing, which allows developers to trace the execution of requests across multiple functions and services.
- Automated Anomaly Detection: Machine learning algorithms will be used to automatically detect anomalies and identify potential problems in serverless applications. These algorithms will analyze historical data to establish baseline performance metrics and flag deviations from these baselines. For example, a system could detect an unusual spike in function execution time or an unexpected increase in error rates, alerting developers to investigate the issue.
- Predictive Analytics for Resource Management: Predictive analytics will be used to forecast resource needs and automatically scale serverless functions to meet demand. This will involve analyzing historical traffic patterns and using machine learning models to predict future resource requirements. This will help optimize costs and ensure that applications have the resources they need to handle traffic.
Focus on Security and Compliance
Security and compliance are paramount concerns in serverless development. Future innovations will focus on enhancing security measures and simplifying compliance efforts.
- Automated Security Scanning and Vulnerability Detection: Automated tools will scan serverless functions and dependencies for vulnerabilities, helping developers identify and address security risks early in the development process. These tools will integrate with CI/CD pipelines to automatically scan code changes and flag any potential security issues. This will include static analysis of code, dependency scanning, and dynamic analysis of running functions.
- Simplified Compliance and Governance: Tools will simplify compliance with regulatory requirements, such as GDPR and HIPAA. These tools will automate the process of auditing serverless applications and generating compliance reports. They will also provide built-in security controls and best practices to help developers build secure and compliant applications. This will involve features like automated policy enforcement, data encryption, and access control.
- Enhanced Identity and Access Management (IAM): IAM systems will become more sophisticated, providing granular control over access to serverless resources. This will allow developers to define precise permissions for each function and service, minimizing the risk of unauthorized access. This will involve features like role-based access control (RBAC) and attribute-based access control (ABAC).
A Futuristic Serverless Development Environment
Imagine a development environment where developers interact with serverless applications through a unified, intelligent interface. This environment would be characterized by the following:
- Holographic Interface: Developers interact with their applications through a holographic interface, visualizing the entire serverless architecture as a 3D model. This model dynamically updates to reflect the current state of the application, including resource usage, performance metrics, and error rates.
- AI-Powered Assistance: An AI-powered assistant proactively provides developers with recommendations, code suggestions, and debugging assistance. The assistant analyzes code in real-time, identifies potential issues, and suggests optimizations.
- Automated Deployment and Testing: Deployment and testing are fully automated, with the system automatically deploying code changes and running tests in a simulated environment. Developers can view the results of tests in real-time and receive feedback on code quality and performance.
- Real-Time Collaboration: Multiple developers can collaborate on the same serverless application in real-time, with changes synchronized automatically. The system provides features for version control, code review, and communication.
- Integrated Security and Compliance: Security and compliance are built into the environment, with automated scanning, vulnerability detection, and policy enforcement. Developers can easily generate compliance reports and ensure that their applications meet regulatory requirements.
This futuristic environment would represent a significant leap forward in serverless DevEx, empowering developers to build and manage serverless applications with greater efficiency, security, and ease. The environment would prioritize user experience, allowing developers to focus on building innovative solutions without being bogged down by the complexities of infrastructure management.
Last Point
In conclusion, the developer experience for serverless applications is a multifaceted landscape shaped by technological advancements, architectural choices, and evolving best practices. From streamlined deployment pipelines to robust monitoring solutions, a well-defined DevEx is crucial for realizing the benefits of serverless computing. By understanding the challenges and embracing the opportunities, developers can build scalable, cost-effective, and resilient applications that leverage the power of serverless technologies.
Continuous learning and adaptation are key to thriving in this dynamic environment.
Questions Often Asked
What are the primary advantages of serverless development for developers?
Serverless development offers benefits such as reduced operational overhead (no server management), automatic scaling, pay-per-use pricing, and increased developer productivity due to simplified deployment and focus on code rather than infrastructure.
How does serverless impact debugging and testing processes?
Debugging serverless applications can be more complex due to distributed nature. Developers rely heavily on logging, tracing, and monitoring tools. Testing involves unit tests, integration tests (often simulating cloud services), and potentially local emulators for faster feedback loops.
What are the key security considerations when developing serverless applications?
Security in serverless focuses on identity and access management (IAM), secure code practices, input validation, and managing dependencies. Developers are responsible for securing their code and configuring access controls to prevent vulnerabilities and data breaches.
How do serverless frameworks simplify the development process?
Serverless frameworks abstract away infrastructure complexities, providing tools for defining functions, managing dependencies, deploying code, and configuring resources. They often offer features like automatic scaling, event handling, and simplified configuration, boosting developer productivity.